Cisco Press


This chapter builds the foundation for the remainder of the book by introducing the concepts and terminology critical to understanding IP traffic plane security. Basic IP network concepts and IP protocol operations are reviewed, including the various packet types found in the network and how these packets apply to different IP traffic planes. Then, packet processing and forwarding mechanisms used by routers are reviewed. Special attention is given to how various packet types within each traffic plane affect forwarding mechanisms. Finally, various router hardware architectures are reviewed, again highlighting how router performance and network security are affected by the IP traffic planes.
IP Network Concepts
Internet Protocol (IP) and IP/Multiprotocol Label Switching (IP/MPLS) packet-based networks capable of supporting converged network services are rapidly replacing purpose-built networks based on time-division multiplexing (TDM), Frame Relay, Asynchronous Transfer Mode (ATM) and other legacy technologies. Service providers worldwide are deploying IP/MPLS core networks to realize the efficiencies and scalability offered by IP networks, and their ability to enable rapid expansion into new service markets. Enterprises are also taking advantage of the end-to-end, any-to-any connectivity model of IP to drive business-changing profit models through infrastructure and operational efficiency improvements, as well as to capture e-commerce opportunities.
Building and operating IP network infrastructures for converged services is a balancing act. Meeting the carrier-class requirements that customers demand, while supporting multiple, diverse services that have distinct bandwidth, jitter, and latency requirements, is a challenging task. Legacy, single-purpose networks were designed and built with specific, tightly controlled operational characteristics to support a single service. Hence, the (typically) single service each network supported usually worked flawlessly. This was relatively easy to achieve because these networks catered to a single application/service that was tightly controlled. Carrying Internet traffic, voice and video traffic, cellular traffic, and private (VPN) business traffic over a common IP backbone has significant implications for both network design and network operations. Disruptions in any one of these traffic services may potentially disrupt any of the other services, or the wider network. Thus, the importance of network security in converged networks is magnified.
Note – The traditional focus areas of network security include confidentiality, integrity, and availability (CIA), in varying degrees, depending on network functions. As network convergence has taken hold, the importance of each of these areas changes.
Availability, for example, is no longer simply a binary “up/down” or “on/off” function, but must now consider other issues such as network latency caused by congestion and processing delays. For example, consider the effects of malicious traffic, or even changes in the traffic patterns of one service, say Internet data. This might cause congestion that affects another service such as Voice over IP (VoIP) traffic traversing the same core routers but in a different services plane (as will be defined later in this chapter). Because one of the prime motives for converging disparate services and networks onto a single IP core is to gain capital and operating expenditure (CapEx and OpEx) efficiencies, this perturbation in availability may lead to a disruption in the entire revenue model if high-value services cannot be supported adequately. This is the basis for developing a different way of thinking about IP network security, one modeled around the IP traffic plane concept.
The concept of IP network traffic planes is best introduced by first considering the features that distinguish IP networks from other network types:
IP networks carry all packets in a common pipe. Fundamentally, all networks have essentially two kinds of packets:
— Data packets that belong to users and carry user or application traffic
— Control packets that belong to the network and are used to dynamically build and operate the network
One of the strengths of the IP protocol is that all packets are carried in a common pipe (also referred to as “in-band”). Legacy networks typically relied on separate channels for data and control traffic. IP does not segment traffic into separate channels. As the subject of this book implies, classifying different traffic types is the first step in segmenting and securing an IP network. Each of these tasks—traffic classification, segmentation, and control—is essential for IP network security.
IP networks provide any-to-any and end-to-end connectivity by nature. In its simplest form, a router provides destination-based forwarding of IP packets. If a router has a destination prefix in its forwarding table, it will forward the packet toward its final destination. Hence, routing (and more specifically, what prefixes are in the forwarding table of the router) is one of the most important, but often overlooked, components of IP network security.
For example, using a default route often has significant implications for network security. The ubiquitous nature of IP, along with its any-to-any, end-to-end operational characteristics, provides inherent flexibility and scalability at unprecedented levels. This is at the same time both a positive and a negative aspect of IP networking. On the positive side, this provides instant global connectivity, which enables innovation and constant evolution. On the negative side, however, this global connectivity also provides unparalleled opportunities for misuse and abuse through these same networks. (In the physical world, one must be proximate to the scene to carry out a crime. This is not the case in the cyber world. Also, one person can do significant damage in the cyber world—in other words, there is a force-multiplier—which the physical world does not offer.)
IP networks use open standards defined by the IETF; access to the protocol standards is freely available to everyone. These standards are independent from any specific computer hardware or operating system. This openness encourages and drives innovation of new applications and services that run over IP networks. This leads to several challenges as well, however. It is often difficult for networks to keep pace with rapidly changing demands. Supporting new applications and services may present challenging new flow characteristics. A few examples include:
— Asymmetric vs. symmetric upstream/downstream bandwidth with peer-to-peer networking
— Increases in absolute bandwidth utilization and unicast vs. multicast packet types with video services
— Tolerance to variations in delay and jitter characteristics for voice services
In addition, networks must be resilient enough to account for abuse, either from misuse, misconfigurations, obfuscation, or outright maliciousness.
These concepts are the driving factors behind this book. In today’s IP networks, it is critical to distinguish between the various traffic types, segment them into various IP traffic planes, and incorporate mechanisms to control their influences on the wider network.
Two broad network categories are highlighted in this book to provide a context for demonstrating the concepts of IP network traffic plane separation: the enterprise network and the service provider network. Although there are similarities between them, the significant differences between them are useful for demonstrating IP traffic plane security concepts and techniques covered in detail in later chapters. The following description of these network types is provided as an overview, simply to introduce the concepts of IP traffic planes. This is not intended as a design primer for enterprise or service provider networks.
Enterprise Networks
Enterprise networks form a large, broad class distinguished by their architectural details and typical traffic flows. Enterprises often build networks to satisfy four goals:
To interconnect internal users and applications to each other
To provide internal users with access to remote sites within the same organization (administrative domain) and, most likely, to the wider Internet as well
To connect external users (Internet) to publicly advertised resources under control of the organization (for example, a web site)
To connect external partners (extranet) to segmented business resources (nonpublic) under the control of the organization
Enterprise networks may be small, medium, or large, and undoubtedly have many internal variations. Yet they also have many common characteristics, including:
A well-defined architecture, typically following the hierarchical three-layer model of core, distribution, and access layers. Here, the core layer provides the high-speed switching backbone for the network, as well as connectivity to the wide-area network, which may consist of the public Internet, an IP VPN, or a private IP network. The distribution layer connects the core and access layers, and often provides a policy-enforcement point for the network. The access layer provides user and server access to local segments of the network. In smaller networks, these three layers are often consolidated.
A well-defined edge that serves as the demarcation for distinguishing enterprise side and provider side (or private and public) from the perspective of both ownership and capital property. It is clear in most cases who owns the devices in a network, what these devices are responsible for, and who is authorized to access these particular devices and services.
A well-defined set of IP protocols, including an Interior Gateway Protocol (IGP) for dynamic routing (such as Open Shortest Path First [OSPF]), network management protocols (such as Simple Network Management Protocol [SNMP], syslog, FTP, and so forth), and other IP protocols supporting enterprise client/server applications and other internal functions.
A well-defined traffic flow running across the network edge (inside-to-outside and outside-to-inside), and traffic flows running exclusively within the interior of the network. The edge almost always serves as a security boundary, and presents an opportunity to constrain traffic flows crossing this boundary based upon defined security policies. Internal traffic flows stay entirely within the enterprise network. Enterprise networks should never have transit traffic flows—that is, packets that ingress the network edge should never have destination addresses that are not part of the enterprise network address space, and hence would simply flow back out of the network.
Figure 1-1 illustrates a common, enterprise network architecture.
These characteristics provide the basis for securing IP traffic planes in enterprise networks, as you will learn in more detail in later sections. In addition, a detailed case study on securing IP traffic planes in enterprise networks is provided in Chapter 8, “Enterprise Network Case Study.”
Conceptual Enterprise Network Architecture
Service Provider Networks
Service provider networks also form a large, broad class distinguished by their architectural details and typical traffic flows. Service provider networks are built for profit. That is, the network is the revenue generator (or facilitates the revenue generation). In order to create revenues, service providers build networks for the following reasons:
To provide transit traffic capacity for their own (enterprise) customers for access to other directly attached (enterprise) customer sites, and to all publicly advertised address space (in other words, the Internet)
To provide traffic capacity and access by external users to content and services directly hosted by the service provider
To provide internal traffic capacity for other converged services owned by the service provider to take advantage of the IP core network
In general, SP networks have the following characteristics:
A well-defined architecture, typically consisting of edge and core routers. The scope of the network usually reaches regional, national, or even global scale, with “points of presence” (PoP) located in strategic locations. The network architecture is built with hardware and physical plant redundancies to provide high availability and fault tolerance. Network capacities support the largest of scales.
A well-defined edge that is the demarcation between provider and customer networking equipment. It is clear in most cases who owns all devices, what these devices are responsible for, and who is authorized to access all particular devices and services. While this is also true for enterprise networks, there are some differences as to how service providers distinguish their networks. Service provider networks have two types of edges. The first is the edge between the service provider network and its customers’ networks. The second is the peering edge, the edge where service provider networks are interconnected. This adds different IP traffic plane complexities because two independent networks with independent IP traffic planes are interconnected. Security is particularly important here.
A well-defined set of IP protocols, including an IGP, and numerous Border Gateway Protocol (BGP) sessions. The IGP runs completely internal to the network and generally never contains customer IP addresses. BGP generally runs between the service provider and enterprise networks, and peering networks, and contains a publicly addressable IP address space. For IP VPNs, an IGP or BGP may be used between customer and service provider. Other IP protocols supporting network management (such as SNMP, syslog, FTP, and so forth), billing, and other internal functions are also defined.
Figure 1-2 illustrates a common, service provider network architecture.
It is interesting to compare service provider networks with enterprise networks because their traffic flows are very different. In many regards, they can be viewed as opposites of one another.
First, enterprise networks almost always present a hard edge to the Internet, where nothing is allowed to cross unless it is either return traffic from internally generated traffic, or tightly controlled externally originated traffic destined to well-defined publicly exposed services. Service providers, on the other hand, are just the opposite. They build their networks to allow all traffic to cross their edge almost without impediment. The edge is designed to be wide open—everything crosses unless it is explicitly forbidden from crossing.
Second, enterprise networks also are built for traffic either to stay completely within the network or to reach the core (interior) of the network. To control this traffic flow, enterprises almost always use stateful devices such as firewalls to control any external traffic flows. Service provider networks, on the other hand, again, are just the opposite. External, customer traffic should never reach any of the core (interior) devices or network elements. Instead, traffic is expected to transit the network—that is, it is expected to be destined to other locations outside the service provider network. In addition, due to the great volume of traffic and the myriad of entrance and exit points found in service provider networks, stateful traffic devices such as firewalls and intrusion protection systems are rarely deployed for transit traffic. The job of the service provider is to forward packets toward their ultimate destination as quickly as possible.
Conceptual Service Provider Network Architecture
These characteristics provide the basis for securing IP traffic planes in service provider networks, as you will learn in more detail in later sections. In addition, a detailed case study on securing IP traffic planes in service provider networks is provided in Chapter 9, “Service Provider Network Case Studies.”
Why is the network design so important? Mainly because the way a network is built—from its topology, to the addressing plan, to the hardware selections—greatly influences how well (or easily) it can be secured. As you will learn, the network design provides the basis from which IP traffic planes can be defined and how they can be secured. Before IP traffic planes can be discussed, however, a quick review of IP protocol operations is required.
IP Protocol Operations
Fundamentally, all networks have essentially two kinds of packets—data packets, which belong to the customer and carry customer application traffic, and control packets, which belong to the network and carry network operational and routing protocol traffic. Of course, further refinement within each of these broad categories is necessary to understand the full complexities of IP network design and protocol operation. But for the moment, this simplified view with just these two traffic types helps illustrate the concepts.
Legacy networks such as Private Line, ISDN, Frame Relay, and ATM use separate control channels and data channels for the purpose of segmenting and carrying these two traffic types. ISDN, for example, uses the delta channel (or D channel) to construct and maintain the network, and the bearer channel (or B channel) to carry customer traffic. Frame Relay uses one control virtual circuit (VC) for the construction and management of all data VCs, and data VCs to carry customer traffic. This hard separation of control traffic from customer data traffic, coupled with a closed, controlled user community, leads to reasonably secure network environments.
While these networks were not immune from attack, the malicious knowledge necessary to actually attack these networks was not well known. In addition, there was no “global reachability” as is the case in IP. Because the network elements were not easily accessible by customer traffic, direct attacks were not easily accomplished. Most security issues were related to misconfigurations, and service disruptions were related to network element hardware or software flaws or basic provisioning (often human) errors. These same attributes also led to inflexibilities and inefficiencies that prevent these networks from surviving in today’s anywhere, anytime global communications world. IP is dominating the networking world due to the simplicity and efficiency resulting largely from its connectionless, any-to-any nature, its open, standards-based architecture, and its universal support over any link-layer technology.
The Internet Protocol technically refers in full to the Transmission Control Protocol/Internet Protocol (TCP/IP) suite. The TCP/IP protocol suite divides the complex task of host-to-host internetworking into layers of abstraction, with each layer representing a function performed when data is transferred between cooperating applications across an internetworking environment. A layer does not typically define a single protocol, but rather a data communications function performed by any number of protocols that could operate at that layer. Every protocol communicates with a peer of the same protocol in the equivalent layer on a remote system. Each protocol is concerned with communicating only to its peer and does not concern itself with the layer above or below, except to the extent that data must be passed between the layers on a single device. The Open System Interconnection (OSI) seven-layer reference model is commonly used to describe the structure and function of the layers used in IP protocol data communications, although for TCP/IP the mapping to seven layers is not exact. The OSI seven-layer model is illustrated in Figure 1-3.
TCP/IP 7-Layer Model
The key features of the seven layers in this model, and their mapping to the TCP/IP protocol suite, are as follows:
Layer 7—application layer: Defines the user (application) process interface for communications and data-transfer services. A very common example of an application layer protocol is HTTP for user applications. Some network control applications also operate at this layer.
Layer 6—presentation layer: Provides data format translation services between dissimilar systems. MIME encoding, data compression, data encryption, and similar data manipulations are described as performing at this layer.
Layer 5—session layer: Manages the establishment and termination of user sessions, including connections between the local and remote applications. TCP uses this layer to provide certain session management functions.
Layer 4—transport layer: Manages end-to-end sessions between local and remote endpoints in the network. Examples include the connection-oriented, reliable, and sequential segment delivery mechanisms with error recovery and flow control provided by TCP, and the connectionless packet delivery mechanisms provided by User Datagram Protocol (UDP).
Layer 3—network layer: Provides the mechanisms for routing variable-length packets between network devices. This layer also provides the mechanisms to maintain the quality of service (QoS) requested by the transport layer, perform data segment fragmentation and reassembly (when required), and report packet delivery and network errors. The IP protocol operates at this layer. Other protocols such as Internet Message Control Protocol (ICMP) and Address Resolution Protocol (ARP) are often described as operating at this layer as well.
Layer 2—data link layer: Provides the mechanisms for transferring frames between adjacent network entities, and may detect and correct frame transmission errors. Although the most common example is Ethernet, other well-known examples include High-Level Data Link Control (HDLC), Point-to-Point Protocol (PPP), and the legacy protocols FDDI and Token Ring.
Layer 1—physical layer: Defines the physical medium over which data is sent between network devices as voltages or light pulses. It includes optical power and electrical voltage levels, cable mechanical characteristics such as layout of pins, and other cable specifications.
As shown in Figure 1-3, each layer plays a role in the process of transporting data across the network. Not every layer is processed by each device along the network, however. In addition, not every protocol operates from end to end. Some are meant for user applications, and these do typically operate from end to end. However, certain protocols are meant for network operations. These may operate in an end-to-end manner, where the endpoints are the network elements themselves, or they may operate in a point-to-point manner between adjacent devices. As you will learn in more detail later, this layering, and the function and operation of the various protocols, is critically important in developing IP traffic plane security strategies.
The fundamental protocols of the TCP/IP protocol suite include:
IP—Layer 3
TCP—Layer 4
UDP—Layer 4
ICMP—Layer 3
IP is a network layer (Layer 3) protocol that contains addressing information and some control information that enables packets to be routed to their final destination. Along with TCP, IP represents the heart of the Internet protocols. As noted earlier, TCP provides connection-oriented transport (Layer 4) services for applications. UDP is also a transport (Layer 4) service, but unlike TCP, UDP provides connectionless transport. ICMP is a control protocol that works alongside IP at the network layer to provide error control and maintenance functions. Of course, many other protocols are relevant in the TCP/IP world, and there are numerous references that describe their uses and operations. Several excellent resources are listed in the “Further Reading” section at the end of this chapter.
Numerous applications (Layer 7) take advantage of the transport (Layer 4) services of TCP and UDP. Some common examples include the following:
Hypertext Transfer Protocol (HTTP): A client/server application that uses TCP for transport to retrieve HTML pages.
Domain Name Service (DNS): A name-to-address translation application that uses both TCP and UDP transport.
Telnet: A virtual terminal application that uses TCP for transport.
File Transport Protocol (FTP): A file transfer application that uses TCP for transport.
Trivial File Transfer Protocol (TFTP): A file transfer application that uses UDP for transport.
Network Time Protocol (NTP): An application that synchronizes time with a time source and uses UDP for transport.
Border Gateway Protocol (BGP): An exterior gateway routing protocol that uses TCP for transport. BGP is used to exchange routing information for the Internet and is the protocol used between service providers.
Because IP is a connectionless protocol, it forwards data in self-contained routable units known as datagrams or packets. Each packet includes an IP header (built by the end station during encapsulation) that contains information (such as source and destination addresses) that is used by routers when making forwarding and policy decisions. The existence of this IP header is why, in a connectionless networking environment, there is no need (as there would be in the legacy networks previously mentioned) for prior setup of an end-to-end path between the source and destination before data transmission is initiated.
The IP packet header normally requires 20 bytes to specify the data necessary to route the packet. The IP header is capable, however, of allowing further optional information to be added to invoke specialized services during packet transit. With certain exceptions, IP options are not normally used. (You will learn much more about IP options and their impact on IP traffic plane security later in this section.) The IP header is shown in Figure 1-4.
IP Packet Header Layer 3
The header fields shown in Figure 1-4 include the following:
IP Version: Indicates the version of IP used by the packet. A value of 4 indicates IP version 4, which is the most prevalent version in use today. A value of 6 indicates the newer IP version 6, which is beginning to become more widely deployed (and likely will dominate IPv4 in the future).
IP Header Length: Indicates the header length in 32-bit words. Typical IPv4 packets with a header length of 20 bytes have a value of 5, meaning five 32-bit (4-byte) words. Recall that the IPv4 header is not a fixed length. It has a minimum length of 20 bytes (an IP Header Length value of 5), but when IP options are included, a maximum length of up to 60 bytes (a value of 15, or 0x0F) may be indicated.
Note – Historically, the variable-length header size of IPv4 packets has always been problematic, for routing and security reasons. It is worth noting that IPv6 has a fixed-length header size of 40 bytes and there is no corresponding Header Length field. The simplified IPv6 fixed-length header is intended to speed processing and resolve many of the security issues associated with IPv4 header options.
Type of Service (ToS): Specifies how an upper-layer protocol would like packets to be queued and processed by network elements as they are forwarded through the network (if so configured). This is usually set to zero (0), but may be assigned a different value to indicate another level of importance.
Total Length: Specifies the length, in bytes, of the entire IP packet, including the data and IP header.
Identification: Contains an integer that identifies the current datagram. This field is used during reassembly of fragmented datagrams.
Flags: Consists of a 3-bit field, the two low-order (least-significant) bits of which control fragmentation. The high-order (first) bit is not used and must be set to 0. The middle (second) “Don’t Fragment” (DF) bit specifies whether the packet is permitted to be fragmented (0 = fragmentation permitted, 1 = fragmentation not permitted). The low-order (third) “More Fragments” (MF) bit specifies whether the packet is the last fragment in a series of fragmented packets (set to 1 for all fragments except the last one, telling the end station which fragment is the last).
Fragment Offset: Provides the position (offset), in bytes, of the fragment’s data relative to the start of the data in the original datagram, which allows the destination IP process to properly reconstruct the original datagram.
Time to Live (TTL): Specifies the maximum number of links (also known as “hops”) that the packet may be routed over. This counter is decremented by one by each router that processes the packet while forwarding it toward its destination. When the TTL value reaches 0, the datagram is discarded. This prevents packets from looping endlessly, as would otherwise occur during accidental routing loops, for example.
Protocol: Indicates which upper-layer protocol receives incoming packets after IP processing is complete. Normally, this indicates the type of payload being carried by IP. For example, a value of 1 indicates IP is carrying an ICMP packet, 6 indicates a TCP segment, and 17 indicates that a UDP packet is being carried by IP.
Header Checksum: A 1’s-compliment hash, inserted by the sender and updated by each router that modifies the packet while forwarding it toward its destination (which essentially means every router because, at a minimum, the TTL value is modified at each hop). The header checksum is used to detect errors that may be introduced into the packet as it traverses the network. Packets with an invalid checksum are required to be discarded by any receiving node in the network.
Source Address: Specifies the unique IP address of the sending node (the originator of the IP packet).
Destination Address: Specifies the unique IP address of the receiving node (the final destination of the packet).
IP Options: Allows IP to support various options, such as timestamp, record route, and strict source route. IP options are not normally used.
The data carried by the IP packet, including any additional upper-layer header information (such as from TCP or UDP, for example), follows this IP header. A more detailed look at the protocol headers for IP, TCP, UDP, and ICMP is included in Appendix B, “IP Protocol Headers.” Appendix B also provides a short discussion on how some of these header values are manipulated for malicious intent and what the security implications may be.
Note – Network security specialists must be extremely well-versed in IP protocol header structures, options, operations, and manipulations. This knowledge is required to understand and mitigate the potential threats against an IP network. Threats are reviewed in Chapter 2, “Threat Models for IP Networks,” and techniques to mitigate risks of attack are reviewed in Section II. Many excellent references cover IP protocol operations in significant detail. One excellent source of information is TCP/IP Illustrated, Volume 1. This and other references are listed in the “Further Reading” section at the end of this chapter.
IP forwarding is based on the destination address in the IP header, and routers are the devices that perform destination-based forwarding in IP networks. IP options also influence routing. A router is a network device that forwards packets downstream to a target destination. It makes its forwarding decisions based on its knowledge of both directly connected networks and networks discovered via routing protocol operations with other routers. A router may consist of many network interfaces that provide connectivity to other network entities, including routers, hosts, network segments, and so forth. As you learned at the beginning of this section, all networks have essentially two kinds of packets, data packets and control packets. You also learned that IP networking carries both kinds of packets in a common pipe (in other words, “in-band”). Thus, a router must look at every single packet entering an interface and decide what type of packet it is—data or control—and apply the appropriate processes to each packet based on this determination. Understanding the details of how routers perform this operation is a key concept in separating and securing IP network traffic planes.
Data packets belong to the customer and carry customer application traffic. Control packets belong to the network and carry network operational and management traffic. Control packets are used by various router functions to create and maintain the necessary intelligence about the state of the network and a router’s interfaces. IP routing protocols provide the framework for gathering this intelligence. Data packets are processed and forwarded by the router using the intelligence and network state created by the control packets. Both functions must be accomplished by every router in the network, and in a coordinated manner. Even though IP networks carry all packets in-band, it is still possible, and perhaps even more critical than ever, to distinguish between the various types of packets being transported by the network.
So how does a router decide what kind of packet it is receiving—essentially, whether it is a data packet or a control packet? In general, this determination is made at the outset by looking at the destination address in the IP header. That is, if the destination address of the packet is meant to terminate on the router itself—every device on the network has at least one IP address of its own—then it is most likely a control packet. If the destination address of the packet is meant to be forwarded out one of the router’s interfaces toward an external destination (from the perspective of an individual router), then the local router treats it as a data plane packet (although it may be a control packet for another downstream router.) Why this matters is that routers are optimized to forward data packets. Control packets, under normal circumstances, form a small percentage of the packets handled by the router. How routers process various packet types is discussed in the IP Traffic Concepts section in this chapter. As you will learn, these processing differences have often profound implications on network security. Chapter 2 discusses these concepts in greater detail.
IP Traffic Concepts
You just learned that IP is connectionless, and that IP encapsulates data in self-contained routable units known as packets. Each packet includes an IP header that contains information (such as source and destination addresses) that is used by routers when making forwarding decisions. You also saw how IP transmits everything in-band. Control and data packets arrive on a common interface and are handled by the same router, but for obviously different purposes. Finally, you learned that, in a simplified way, routers process each packet based on its destination address. From the perspective of any single router, if a packet has a destination of the router itself, it is most likely a control packet, and if the destination is somewhere else in the network, it is treated as a data packet and forwarded. Of course, this is a very simplified view of IP network operations. Achieving a full understanding of how IP traffic plane separation and control impacts IP network security requires a deeper investigation of network and router operations.
As illustrated in Figure 1-5, a single router participates in a larger network environment, possibly even the Internet. Thus, individual routers, by themselves, may or may not understand the full context of each IP packet they are processing (in other words, in which IP traffic plane the packet belongs). What is relevant from each router’s perspective, at the very moment it is processing any individual packet, is the IP traffic type it is seeing. The concept of traffic planes is a logical one, not a physical one. The concept of traffic type is a real one, and is the focus of this section.
How routers actually process different packet types must be fully understand. Why do routers process some packets differently from others? What are the security implications resulting from differences? These are the concepts that require a more in-depth understanding for the three broad categories: transit, receive, and exception packets.

IP Networking Perspective
Transit IP Packets
IP networks are built to forward packets between end hosts. What a router does, primarily, is take packets in one interface, look at the destination field in the IP header, look for a match with a destination network in the routing table (built by the control plane!), and forward the packet out the appropriate interface that gets the packet one hop closer to its final destination.
In the case of transit packets, the destination network is somewhere off the router. That is, the IP address is not owned by the particular router processing the packet, but rather is somewhere else in the network. The destination could be on a directly attached subnet (LAN), or it could be many downstream hops away. The key is that the packet is not destined to this router but, more accurately, through this router. Hence, when a router sees a transit packet, the decision it makes is to forward the packet out one of its interfaces. Routers typically use specialized forwarding hardware and algorithms to accomplish this forwarding function as quickly as possible. Additional details on router forwarding architectures are discussed in the “General IP Router Architecture Types” section of this chapter.
You should note that there is no explicit or implicit statement here about what IP traffic plane these transit packets are part of. From the perspective of a single router, transit packets may be of any IP traffic plane, as you will see shortly. Consider the example of a management session between a Secure Shell (SSH) client in the network operations center (NOC) and a router in the core of the network. The management session packets traverse many routers on their way to the destination router. Hence, they are transit packets according to every router along the path, until they reach the final core router. On that final router, they are no longer transit packets but are receive or receive-adjacency packets. (See the following section.) Yet, as you will learn shortly, it is clear from a logical perspective that these packets are all part of the management plane from a traffic plane perspective.
Receive-Adjacency IP Packets
IP packets that arrive at a router and that are destined to an IP address owned by that router itself as the final destination are called receive-adjacency packets.
Note – The term receive packet, or receive-adjacency packet, comes from nomenclature used by the adjacency table created by the Cisco Express Forwarding (CEF) forwarding mechanism. When CEF builds its adjacency table, it lists IP addresses for interfaces (both physical and logical) that are owned by the router as “receive.” Another term used in some documentation is “for-us” packets. CEF is discussed in more detail later in this section.
When a router sees receive-adjacency packets, the destination address of the packet is always something that the router itself owns. It could be the IP address of a physical interface or of a logical interface such as a loopback interface or tunnel interface. These packets could have arrived from a host on a directly connected LAN, or they could have arrived after traversing several or many upstream routers to get to this final router. Either way, the decision the router makes when it sees receive-adjacency packets is very different from the one it makes for transit packets. With receive-adjacency packets, the router cannot engage any specialized forwarding hardware; the router must process the packet itself, using its own local CPU resources.
Note – The term often used in documentation to describe moving a packet from the normal, high-speed forwarding path to the router’s own CPU for local processing is punt. For example, you may read that some types of packets are “punted to the CPU for processing.” This terminology will be used in this book as well.
Although it may seem that all receive packets are control packets, this is not the case. As with transit packets, many kinds of packets potentially fall into the receive category. Receive packets generally include traffic in the control, management, and services planes.
The most important concept to understand with receive packets is that the router must treat them differently from transit packets. Usually, this implies that the router is using different hardware and/or software to process these packets and, nearly always, that the speed of processing is much slower than for transit packets. How receive and transit packet processing interactions affect the overall performance of the router, and the implications this has on network security, is one of the main reasons why IP traffic plane segmentation and control is so critical.
Exception IP and Non-IP Packets
In the preceding two sections, you learned about two different traffic types, transit and receive. Traffic in the transit family includes packets that the router forwards on toward some final destination, typically using some high-speed forwarding mechanism. Traffic in the receive family includes packets that the router must process itself locally. Interestingly, these two traffic types do not cover all cases in IP networks. Two other traffic types also seen by routers include the catch-all group known as exception IP packets, and the non-IP packets group.
Exception IP packets include transit or receive IP packets that have some exceptional characteristic about them and that cannot be handled by normal processing by the router. Non-IP packets are basically just that—packets that are not part of the IP protocol. These typically are used by the routers themselves to construct and maintain the network. Why exception IP and non-IP traffic types are so important is that routers process these packets in a different way from how they process normal transit or receive packets. These packets are important because each has the potential to impact the network. They can move data, they can help build routing tables, and they can control routers. These all potentially have security implications. Several examples will help illustrate this point.
Exception IP Packets
An example of an exception IP packet is as follows: An IP packet arrives at the router, and it is determined to be a transit packet (in other words, the router wants to forward it downstream). However, the TTL field in the IP header has a value of 1. Because the router is required to decrement the TTL field prior to forwarding the packet, the resultant value would be 0. The IP networking protocol requires that packets with TTL = 0 must be dropped. In addition, an ICMP error message must be generated and sent back to the originator of the packet to inform them that the packet was dropped. The specific ICMP error message is the “time exceeded in transit” message, or ICMP Type 11, Code 0. (See Appendix B for complete details on ICMP error messages.) The exception condition here is due to the fact that the router must alter its normal transit packet processing to drop the expired packet and generate and send the correct ICMP message back to the source of the original packet. This exception process requires the router to expend additional resources it would otherwise not expend, simply to forward the packet.
Other examples include: IP packets containing options in their header field, IP packets requiring fragmentation, and IP multicast packets used to create state. There are other exceptions as well, and these vary between router platforms.
Non-IP Packets
The other group of exception packets includes non-IP packets. In general, there are two groups of non-IP packets that routers may need to process. The first group includes the Layer 2 packets that are generated by the routers themselves to construct and maintain the network. Examples of packets of this type include:
Layer 2 keepalives: Cisco HDLC, Frame Relay, ATM Operation, Administration, and Maintenance (OAM), and other Layer 2 protocols typically send periodic L2 messages to convey interface up/down status between devices.
Link Control Protocol (LCP): LCP is an integral part of PPP and Multilink PPP (MLP), and provides automatic configuration of the interfaces such as setting datagram size, escaped characters, and magic numbers, and selecting (optional) authentication. LCP can also detect a looped-back link and other common misconfigurations, and terminate the link.
Cisco Discovery Protocol (CDP): CDP is a proprietary protocol that transmits router hardware, software, and interface status information between adjacent routers via multicast Layer 2 frames.
The preceding examples use purely Layer 2 frames, which are handled as exceptions by the router (punted and handled by the router CPU).
Note – All of the Layer 2 packets just described are local packets, meaning point-to-point packets that are processed by the local router CPU. This distinguishes them from Layer 2 packets that are tunneled (for example, AToM, VPLS, and L2TPv3).
The other group of non-IP packets includes all Layer 3 “non-IP” packets that may be configured to run on the router concurrently with IP.
Examples of non-IP Layer 3 protocols include:
Intermediate System-to-Intermediate System (IS-IS): An IGP used by many large service providers to maintain routing information within their own network administrative domain (instead of OSPF) to support reachability between BGP next-hops. IS-IS operates at Layer 3 like IP, but is a separate protocol that was originally developed by the International Organization for Standardization (ISO) as a routing protocol for Connectionless Network Protocol (CLNP) as part of Connectionless Network Services (CLNS). It was later extended to support IP routing, and is referred to as Integrated IS-IS.
Address Resolution Protocol (ARP): Used by hosts to find the corresponding Layer 2 (hardware) address to an IP network (Layer 3) address.
Multiprotocol Label Switching (MPLS): A data-carrying mechanism that emulates some of the properties of a circuit-switched network. MPLS is generally considered to operate between the traditional definitions of Layer 2 and Layer 3 protocols.
Other examples of non-IP Layer 3 protocols include: Novell Corporation’s Internetwork Packet Exchange (IPX) and Apple Corporation’s AppleTalk protocol.
As you have just seen, four distinct traffic types must be handled by routers: transit traffic, receive traffic, exception IP traffic, and non-IP traffic. The primary reason these four types of traffic are described separately here is that routers process these packets in different ways. Router vendors, such as Cisco, build hardware and software to handle all types of traffic within acceptable performance bounds appropriate for a given cost structure. At the same time, network architects and operators must be aware of the interactions between these four traffic types and understand the effects each may have on router and network performance and availability. For example, certain denial-of-service (DoS) attacks may be based on the purposeful manipulation of IP protocol exception packets. Routers and network infrastructure must be designed and built to efficiently forward “normal” traffic, while at the same time handle exception traffic and mitigate attack traffic without adverse impact.
IP Traffic Planes
Sufficient background has been covered to now fully explore the concepts of IP traffic planes. What types of IP traffic planes are there? Why should network traffic be segmented into IP traffic planes? What types of traffic are found in each traffic plane? These are the questions answered here.
Traffic planes are logical separations used to classify traffic based on the function it performs in the network. This approach is used for several reasons. First, it provides a consistent basis from which security policies can be developed. Second, it provides the basis for transforming these security policies into actual network control functions that can be implemented on various network elements.
As you saw in the previous discussion, depending on where a router is in the network, it will have a different perspective on what type of packet it is processing (transit vs. receive, for example). However, whether a packet is transit or receive does not automatically give any indication as to the function each packet is ultimately supporting. It is the concept of IP traffic planes that provide this end-to-end framework. Packets in each traffic plane have certain requirements that must be enforced, regardless of where they are within the network. Four distinct IP traffic planes are defined: the data plane, the control plane, the management plane, and the services plane. Each has its own distinctive characteristics, and its own security requirements. The four IP traffic planes are described in detail next.
Data Plane
The data plane is the logical entity containing all “customer” application traffic. In this context, customer traffic refers to traffic generated by hosts, clients, servers, and applications that are intended to use the network as transport only. Thus, data plane traffic should never have destination IP addresses that belong to any networking devices (routers, switches), but rather should be sourced from and destined to other devices, such as PCs and servers, that are supported by the network. The primary job of the router in the case of the data plane is simply to forward these packets downstream as quickly as possible. Figure 1-6 illustrates the basic concepts of the data plane.
Data Plane
Networks are built and operated to support data plane traffic. Without the data plane, there is no need for a network. First and foremost, the data plane must be “available.” As you will see shortly, the data plane depends on the control plane and, to a certain extent, the management plane. Thus, interdependencies exist between these planes and they must be considered. In addition, there may be a “confidentiality” requirement, which may be satisfied via data separation (as would be provided by Frame Relay or MPLS VPNs, for example) or encryption. This is discussed further in the “Services Plane” section.
Data plane traffic always includes transit packets. Under normal conditions, transit traffic should account for a large percentage of all data plane traffic. This is precisely why routers often use specialized forwarding hardware and algorithms to accomplish this forwarding function as quickly as possible. That does not imply that all transit packets belong to the data plane, or that the data plane consists only of transit packets. There are exceptions, and in this case, routers may be required to perform some additional work to forward certain data plane packets. Hence, the data plane may also include certain (transit) exception packets. When this occurs, additional router resources are required to forward data plane traffic. Two examples will help clarify this point:
Example 1: A packet enters the router’s interface, and the router determines that it is a transit packet that needs to be delivered to a host on a directly connected Ethernet LAN segment. However, the router does not have an ARP entry for the destination IP address. In this case, the router must use its control plane to “ARP” for the destination MAC address. Once the MAC address has been obtained, the packet (and all subsequent packets destined to this IP address) can be forwarded directly without further “exceptions.”
Example 2: A packet enters an interface on the router that has a maximum transmission unit (MTU) of 1500 bytes. The router determines that the transit packet should be forwarded out an interface with an MTU of 1300 bytes. This requires the router to fragment the packet. Thus, the router must determine whether this is allowable by first checking the DF (Don’t Fragment) bit in the IP header (see Figure 1-4). If the DF bit is set to 0, the packet must be fragmented by the router and then forwarded. If the DF bit is set to 1, the router must drop the packet and then generate an error message of ICMP Type 3, Code 4 (Fragmentation Needed, Don’t Fragment Set) and send it to the packet source. Either event causes additional router processing resources to be consumed.
As you can see even with just these two examples, legitimate data plane traffic can impact the performance of a router or a network by causing exception conditions that the router must fulfill through special processing. Most security books describe methods for protecting data plane traffic from various attacks. There is also the need to protect the router and network from data plane traffic under exception conditions. An effective data plane security policy must accomplish both goals.
Data plane traffic must be separated and controlled to protect the router and network against many threats. These threats can come from legitimate traffic and malicious traffic, and the data plane security policy must be prepared for either case. When the router or network performance is impacted, does it matter whether malicious traffic or legitimate traffic caused the problem? Not to the other users of the network. Thus, data plane security must ensure the delivery of customer traffic, and ensure that customer traffic, whether legitimate, malformed, or malicious, does not interfere with the proper operation of the network. Chapter 2 provides additional discussion on some of the threats to the data plane. Chapter 4, “Data Plane Security,” provides detailed descriptions of the current best practices for securing the data plane.
Control Plane
The control plane is the logical entity associated with routing processes and functions used to create and maintain the necessary intelligence about the state of the network and a router’s interfaces. The control plane includes network protocols, such as routing, signaling, and link-state protocols, that are used for communication between network elements, and other control protocols that are used to build network services. Thus, the control plane is how the network gets dynamically built, and provides the mechanisms for routers to understand forwarding topologies and the operational state of the network. Without the control plane, no other traffic planes would function. Figure 1-7 illustrates the basic concepts of the control plane.

Control Plane Example
The control plane always includes receive packets. Receive packets are both generated and consumed by various control processes running on the router. These may include Layer 3 packets for routing protocol processes such as OSPF and BGP, or for other processes that maintain the forwarding state such as Protocol Independent Multicast (PIM), Label Distribution Protocol (LDP), and Hot Standby Routing Protocol (HSRP).
The control plane also includes transit packets. For example, multihop eBGP packets traverse several intermediate routers between peers, and thus have transit characteristics from the perspective of the intermediate routers along their path. These eBGP packets are not destined for processes running on the intermediate routers, yet they are undoubtedly part of the control plane for the overall network. Other examples include mechanisms such as OSPF virtual-link and Resource Reservation Protocol (RSVP). ICMP is the part of the control plane that typically generates messages in response to errors in IP datagrams or for diagnostic or routing purposes.
The control plane also includes certain Layer 3 non-IP packets, such as the routing protocol IS-IS, and ARP, and the Layer 2 packets such as Layer 2 keepalives, CDP, ATM OAM, and PPP LCP frames.
Note – The control plane is typically associated with packets generated by the network elements themselves. End users typically do not interact with the control plane. The ICMP ping application is one exception where a control plane protocol may be directly employed by end users. The ping application allows end users to directly interact with the control plane to determine network reachability information.
Securing the control plane is critical to both router and network operations. If the control plane is compromised, nothing can be guaranteed about the state of the network. Compromises in the control plane may adversely affect the data plane, management plane, and services plane. This could lead to the following:
Service disruption: Data not being delivered
Unintended routing: Data traversing adversary networks for packet sniffing, rogue DNS use, and Trojan/malware insertion, for example
Management integrity issues: Billing, service theft, and so forth
How exposed the control plane is depends greatly on the device location and reachability. For example, routers on the edge of a service provider (SP) network are more exposed than those deep within the SP core simply because they are directly adjacent to uncontrolled customer and peering networks. Enterprise routers also have similar points of increased risk at the Internet edge. Certain Layer 2 vulnerabilities exist as well. These issues and others are described in Chapter 2. In addition, Chapter 5, “Control Plane Security,” provides detailed descriptions of the current best practices for securing the control plane.
Management Plane
The management plane is the logical entity that describes the traffic used to access, manage, and monitor all of the network elements. The management plane supports all required provisioning, maintenance, and monitoring functions for the network. Like the other IP traffic planes, management plane traffic is handled in-band with all other IP traffic. Most service providers and many large enterprises also build separate, out-of-band (OOB) management networks to provide alternate reachability when the primary in-band IP path is not reachable. These basic management plane concepts are illustrated in Figure 1-8.
Management Plane Example
The management plane always includes receive packets. Receive packets are both generated and consumed by various management processes running on the router. As you might imagine, traffic such as SSH (please do not use Telnet!), FTP, TFTP, SNMP, syslog, TACACS+ and RADIUS, DNS, NetFlow, ROMMON, and other management protocols that the NOC staff and monitoring applications use is included in the management plane. In addition, from the perspective of some routers, transit packets will also be part of the management plane. Depending on where the management servers and network operations staff are located, all of the preceding management protocols appear as transit packets to intermediate devices and as receive packets to the destination devices. However, management plane traffic typically remains wholly “internal” to the network and should cross only certain interfaces of the router. Further details on this topic are covered in the case studies presented in Chapters 8 and 9. The management plane should rarely include IP exception packets (MPLS OAM using the Router Alert IP options is one exception). It may however, include non-IP exception packets. CDP is a Layer 2–based protocol that allows Cisco routers and switches to dynamically discover one another.
Securing the management plane is just as critical for proper router and network operations as securing the control plane. A compromised management plane inevitably leads to unauthorized access, potentially permitting an attacker to further compromise the IP traffic planes by adding routes, modifying traffic flows, or simply filtering transit packets. Attackers have repeatedly demonstrated their ability to compromise routers when weak passwords, unencrypted management access (for example, Telnet), or other weak management plane security mechanisms are used. Remember, access to routers is like getting the “keys to the kingdom!” Additional discussions on some of the threats to the management plane are provided in Chapter 2, and Chapter 6, “Management Plane Security,” provides detailed descriptions of the current best practices for securing the management plane.
Services Plane
Network convergence leads to multiple services of differing characteristics running over a common IP network core. Where this is the case, these can be treated within a “services plane” so that appropriate handling can be applied consistently throughout the network. The services plane is the logical entity that includes customer traffic receiving dedicated network-based services such as VPN tunneling (MPLS, IPsec, and Secure Sockets Layer [SSL]), private-to-public interfacing (Network Address Translation [NAT], firewall, and intrusion detection and prevention system [IDS/IPS]), QoS (voice and video), and many others. These basic services plane concepts are illustrated in Figure 1-9.
Services plane traffic is essentially “customer” traffic, like data plane traffic, but with one major difference. The services plane includes traffic that is intended to have specialized network-based functions applied, and to have consistent handling applied end to end. Data plane traffic, on the other hand, typically receives only native IP delivery support. Because different kinds of services may be represented, different polices may need to be created and enforced when working with the services plane.

Services Plane Example
Services plane traffic is generally “transit” traffic. But routers and other forwarding devices typically use special handling to apply or enforce the intended policies for various service types. That is, services plane traffic may be processed in a very different manner from regular data plane traffic. The following examples help illustrate this point:
Encrypted tunnels using SSL or IPsec. Internal redirection to specialized cryptographic hardware, may be required to support SSL or IPsec VPNs. This often creates additional CPU and switching overhead for certain devices. Service encapsulation in tunnels often changes the nature of the traffic from transit to receive as packets now terminate on the network devices for decapsulation. This too can impact the processing operations of certain devices.
Routing separation using MPLS VPN. Routers participating in MPLS VPN services must maintain virtual routing and forwarding (VRF) instances for each customer. This requires additional memory, and can create additional packet overhead due to encapsulation that may result in fragmentation.
Network-based security via firewalls, intrusion protection systems (IPS), and similar systems. The application of network-based security services oftentimes impacts the traffic-flow characteristics of the network. Firewalls and IPS typically require symmetric traffic-flows (egress traffic following the same path as the ingress traffic). Symmetric traffic flows are not inherent to IP and must be artificially enforced.
Network-based service-level agreements (SLA) via QoS: QoS provides virtual class of service (CoS) networks using a single physical network. The application of QoS polices impacts other, non-QoS traffic due to modifications in packet-forwarding mechanisms as latency and jitter budgets are enforced.
Because services planes often “overlay” (Layer 7) application flows on the foundation of lower layers, services planes often add to the control plane and management plane burdens. For example, MPLS VPNs (RFC 4364) add control plane mechanisms to BGP for routing separation, and LDP and RSVP for forwarding path computation. IPsec VPNs add Internet Key Exchange (IKE) mechanisms to the control plane for encryption key generation, and tunnel creation and maintenance. Additional support in the management plane is also required. Tunnel management for IPsec VPNs requires interfacing with each router involved in the service delivery. Similarly, MPLS OAM is required for end-to-end label switch path verification. Other services add different control plane and management plane burdens.
Securing the services plane is critical to ensure stable and reliable traffic delivery of specialized traffic flows. In some cases, this may be straightforward. Encapsulating user-generated IP traffic within a common service header allows for a simplified security approach. Policies need to look only for the type of service, not at the individual user traffic using the service (as in the data plane case). In some cases, this encapsulation may add protections to the core network, because the relatively “untrusted” user traffic can be isolated in a service wrapper and cannot touch the network infrastructure. For example, MPLS VPNs separate per-customer routing functions and network infrastructure routing functions. Dependencies between the services plane and the control plane and management plane add complexities that must be considered carefully. Chapter 2 provides additional discussion on some of the threats to the services plane, and Chapter 7 provides detailed descriptions of the current best practices for securing the services plane.
IP Router Packet Processing Concepts
The last topics to be discussed in this introductory chapter are those of router software and hardware architectures. This will tie together all of the preceding concepts, and illustrate why IP traffic plane separation and control is so vital to the stability, performance, and operation of IP networks.
Routers are built to forward packets, whether in the data plane or services plane, as efficiently as possible. These same routers must also build and maintain the network through the control plane and management plane. The concept of IP traffic planes is a “logical” one, and provides a framework within which to develop and enforce specific security requirements. As illustrated in Figure 1-5 earlier in the chapter, IP traffic plane security concepts can be viewed from the Internet perspective down to the individual router perspective. Where is traffic originated and where is it destined? Where are the network boundaries and what traffic should be crossing those boundaries? Which IP addresses should be included and advertised in various routing protocols? These and many more questions are discussed and answered in the following chapters.
One of the most important areas in this process, and the reason for the perspective view previously shown in Figure 1-5, is that individual routers handle the actual packets in the network. At the end of the day, these devices can only act in an autonomous manner consistent with their hardware, software, and configurations. Understanding how an individual router handles each packet type reaching its interfaces, and the resources it must expend to process these packets, is a key concept in IP traffic plane security.
Although this section focuses specifically on Cisco routers, these concepts are by no means exclusive to Cisco platforms. Every network device that “touches” a packet has a hardware and software architecture that is designed to process a packet, determine what exactly it is required to do with the packet, and then apply some policy to the packet. The term “policy” in this context means any operation applied to the packet, generally including: forward/drop, shape/rate-limit, recolor, duplicate, and tunnel/encapsulate.
A router’s primary purpose is to forward packets from one network interface to another. Each network interface represents either a directly connected segment containing hosts and servers, or the connection to another routing device toward the next hop along the downstream path to the ultimate destination of the packet. In the most basic sense, the Layer 3 decision process of an IP router includes the following steps:
A packet comes into an interface.
The IP header checksum is recomputed and compared to validate the packet integrity. If it does not compare, the packet is dropped.
If it does compare correctly, the IP header TTL is decremented and the checksum is recomputed (because the header data changes with the new TTL value).
The new TTL value is checked to ensure that it is greater than 0. If it is not, the packet is dropped and an ICMP Type 11 message (time exceeded) is generated and sent back to the packet source.
If the TTL value is valid (>=1), a forwarding lookup is done using the destination address. That destination could be to somewhere beyond the router (a transit packet) or to the router itself (receive packet). If a match does not exist, the packet is dropped and an ICMP destination unreachable (type 3) is generated.
If a match is found, appropriate Layer 2 encapsulation information is prepared, and the packet is forwarded out the appropriate interface (transit). In the case of a “receive” destination, the packet is punted to the router CPU for handling.
This process is illustrated in Figure 1-10.
Simple IP Forwarding Example
Of course, the actual packet processing flow can be significantly more complex than this as memory, I/O hardware, IP packet variations, configured polices, and many other factors affect packet processing. Normally, the great majority of all packets in the network are related to the data plane and services plane. Control plane and management plane traffic make up a small portion of overall network traffic. Exception cases exist where data plane packets may require additional control plane resources, or where packets cannot be handled by the normal packet-forwarding mechanisms. In general, routers handle transit, receive, and exception packets in different ways. As you may imagine, routers are optimized to process transit traffic with the most efficiency and speed. But it is how a router handles receive and exception cases that gives you a full understanding of the performance envelop (and vulnerabilities or attack vectors) of the router.
Most Cisco routers use Cisco IOS Software to perform packet-switching functions. (IOS XR is available on high-end routing platforms, including CRS-1 and XR 12000, and was developed for the carrier class requirements of service providers.) When IOS was first developed, only a single switching mechanism existed. This method, known as process switching, was very simple and not very efficient. As network speeds and the demand for higher performance grew, enhancements were made to Cisco IOS Software that provided improved methods of switching. Specialized hardware components were also developed and incorporated into certain routers to improve forwarding performance. Today, Cisco routers are available that switch between thousands of packets per second (Kpps) to hundreds of millions of packets per second (Mpps). Dedicated hardware-based forwarding engines, mainly implemented as application-specific integrated circuits (ASIC), are necessary to achieve the highest forwarding rates. Other parameters, such as I/O memory speed and bus performance, can have a big impact on switching performance. The challenge is to create the highest possible switching performance within the limits of available ASIC, CPU, I/O bus, and memory technology and cost. The switching method used by various Cisco routers to achieve these rates depends on the specific routing platforms.
In general, three switching methods are available in Cisco IOS today:
Process switching: Packets are processed and forwarded directly by the router CPU.
Fast switching: Packets are forwarded in the CPU interrupt, using cache entries created by process switching.
Cisco Express Forwarding (CEF): Packets are forwarded using a precomputed and very well-optimized version of the routing table.
Each of these three switching methods is reviewed in general detail next. The intent of this review is not to describe all the optimizations and mechanisms used by each in forwarding packets. Many excellent references cover these aspects already. Check the “Further Reading” section at the end of this chapter for specific recommendations. The intent is to investigate how these three switching methods deal with packets in the various IP traffic planes, and to see what impact this has on router performance and, hence, network stability and security.
Process Switching
The oldest and most basic switching mode is process switching, also referred to as “slow path” switching. Process switching refers to switching packets by queuing them to the CPU on the route processor and then having the CPU make the forwarding decisions, all at the process level. The term “route processor” is used to describe the module that contains the CPU, system software, and most of the memory components that are used by the router to forward packets. In the process switching model, every packet-switching request is queued alongside all other applications and serviced, in turn, by the software running on the CPU on the route processor.
Figure 1-11 illustrates the steps, listed next, involved in forwarding packets by process switching:
Process switching begins when the network interface hardware receives the packet and transfers it into I/O memory. This causes the network interface hardware to interrupt the CPU, alerting it to the ingress packet waiting in I/O memory requiring processing. IOS updates its inbound packet counters.
The IOS software inspects the packet header information (encapsulation type, network layer header, and so on), determines that it is an IP packet, and places it on the input queue for the appropriate switching process.
The CPU performs a route lookup (Layer 3). Upon finding a match, the CPU retrieves the next-hop address from the routing table (Layer 3) and the Media Access Control (MAC) address (Layer 2) associated with this next-hop address from the ARP cache, and builds the new header. The CPU then queues the packet on the outbound network interface.
The outbound network interface hardware senses the buffered packet, dequeues it from I/O memory, and transmits it on to the network. It then interrupts the main processor to indicate that the packet has been transmitted. IOS then updates its outbound packet counters and frees the space in I/O memory formerly occupied by the packet.
You may already recognize that, although straightforward, process switching has many deficiencies in terms of performance as a switching method. First, each and every packet is switched according to the process described in the preceding list. Any subsequent packets belonging to the same flow are also switched using the exact same switching process. In this basic scheme, no mechanisms are available to recognize that subsequent packets may be part of an already-established flow, and that Layer 3 route-lookups and Layer 2 MAC lookups have previously been performed. Second, because process switching requires a routing table lookup for every packet, as the size of the routing table grows, so does the time required to perform any lookup (and hence the total switching time). Recursive routes require additional lookups in the routing table, further increasing the length of the lookup time.

Illustration of Process Switching
From an IP traffic plane perspective, it should be clear that process switching performs identical functions, initially, for every packet in any IP traffic plane, regardless of the packet type, because each and every packet must be processed by the CPU. Depending on the traffic plane and packet type, however, once IOS inspects the packet header, it determines which software process to hand the packet off to. At this point, additional processing is generally required for certain packets, possibly affecting overall router performance.
Data plane: Data plane packets with transit destinations are handled by process-switching operations exactly as Figure 1-11 illustrates. Because the CPU has finite clock cycles available for switching packets, computing routes, and performing all other functions it is required to, forwarding performance is limited by CPU utilization and can vary. There is also an upper limit on packet forwarding that is a maximum number of packets per second (pps), regardless of interface bandwidth values. This concept is explored further in Chapter 2. Additional processing is required to handle data plane exception packets as well. For example, TTL = 0 packets must be dropped and an ICMP error message must be generated and transmitted back to the originator. Packets with IP options may also require additional processing to handle the header option. When the ratio of exception packets becomes large in comparison to normal transit packets, forwarding performance may be impacted. Thus, controlling the impact of data plane exception packets in particular will be critical in protecting router resources. Chapter 4 explores these concepts in detail.
Control plane: Control plane packets with transit destinations are processed exactly like data plane transit packets. Control plane packets with receive destinations and non-IP exception packets (for example, Layer 2 keepalives, IS-IS, and so forth) also follow the same initial process-switching operations illustrated in Figure 1-11. However, once packet identification determines these are receive or non-IP packets, they are handed off to different software elements in the CPU, and additional resources are consumed to fully process these packets. For example, frequent routing protocol updates (as may occur when interfaces are flapping) will cause routing advertisements and path recomputations and result in temporarily high CPU utilization. High CPU utilization may result in dropped traffic in the data plane if the router is unable to service forwarding requests. Proper network design should minimize routing instabilities. For process-switching platforms, it is critical to prevent spoofed and other malicious packets from impacting the control plane, potentially consuming router resources and disrupting overall network stability. Chapter 5 explores these concepts in detail.
Management plane: Management plane packets with transit destinations are processed exactly like data plane transit packets. Management plane packets with receive destinations also follow the same initial process-switching operations described for the control plane. However, once packet identification determines these are receive packets, they are handed off to software elements in the CPU that are responsible for the appropriate network management service. Management plane traffic typically does not contain IP exception packets (MPLS OAM using the Router Alert IP options is one exception), but may contain non-IP (Layer 2) exception packets (generally in the form of CDP packets). In general, management plane traffic should have little impact on CPU performance. It is possible that some management actions, such as conducting frequent SNMP polling or turning on debug operations, or the use of NetFlow may cause high CPU utilization. Carefully defined acceptable use policies for production networks should prevent unintentional CPU impacts. However, because management plane traffic is handled directly by the CPU, the opportunity for abuse makes it critical that management plane security be implemented. Chapter 6 explores these concepts in detail.
Services plane: Services plane packets follow the same initial process-switching operations illustrated in Figure 1-11. However, services plane packets generally require special processing by the router. Examples include performing encapsulation functions (for example, GRE, IPsec, or MPLS VPN) or performing some QoS or policy routing function. This requires services plane packets to be handled by different software elements in the CPU, incurring additional, possibly heavy, CPU resources. In general, process switching services plane packets can have a large impact on CPU utilization. The main concern then is to protect the integrity of the services plane by preventing spoofed or malicious packets from impacting the CPU. Chapter 7 explores these concepts in detail.
Although process switching contains the least amount of performance optimizations and can consume large amounts of CPU resources, it does have the advantage of being platform-independent, making it universally available across all Cisco IOS–based products. Still, from a performance perspective, process switching leaves a lot to be desired. You may have noticed in the process-switching flow illustrated in Figure 1-11 that three key pieces of information are required to switch any packet:
Destination network reachability: A route must exist in the forwarding table for the destination address.
Egress interface: If a route exists, the IP address of the next hop toward the destination must be known.
Next-hop Layer 2 address: The Layer 2 (for example, MAC) address of the next hop must also be known.
This information is determined for each packet forwarded by process switching, even if the previous packet required the exact same information. In most IP networks, flows normally consist of multiple packets. What if the results of one of these lookups, essentially reachability/interface/MAC combinations, were temporarily saved in a small table? Could substantial reductions in forwarding time be achieved for most of the incoming packets? This is the idea behind fast switching in IOS.
Fast Switching
Fast switching is a software enhancement to process switching that speeds the performance of packets using the forwarding path. You may also see this referred to as “fast cache switching.” Fast switching uses a route cache to store information about packet flows. The route cache is consulted first in each forwarding attempt, instead of using the more expensive, process switching lookup procedures described in the previous section.
Figure 1-12 illustrates the steps, listed next, involved in forwarding packets by fast switching:
Fast switching begins exactly like process switching. First, the network interface hardware receives the packet and transfers it into I/O memory. The network interface interrupts the CPU, alerting it to the ingress packet waiting in I/O memory for processing. IOS updates its inbound packet counters.
The IOS interrupt software inspects the packet header information (encapsulation type, network layer header, and so forth) and determines that it is an IP packet. Instead of placing the packet on the input queue for CPU processing, however, the interrupt software consults the fast cache for an entry matching the destination address. If an entry exists, the interrupt software retrieves the Layer 2 (MAC) and outbound interface information out of the fast cache and builds the new Layer 2 header. Finally, the interrupt software alerts the outbound interface.
Like process switching again, the outbound network interface hardware senses the packet, dequeues it from I/O memory, and transmits it on to the network.

Illustration of Fast Switching
Note that if the destination address is not found in the cache, the router reverts to process switching to forward the packet using the procedures described in the preceding section. One difference, however, is that when fast switching is enabled, after process switching completes, a new entry is made in the fast cache (route cache) for future use. That is, the first packet of any new flow is always process switched. Subsequent packets are fast switched.
Fast switching separates the expensive CPU-based routing procedures from the relatively simple, interrupt-process driven forwarding procedures. This is why fast switching is often referred to as a “route once, forward many” process. Fast switching cache entries are created and deleted dynamically. A new cache entry is created when the first packet to a given destination is process switched and the ip route-cache command is enabled on the output interface. A route cache entry can be deleted when it has not been used for some time (idle timeout), and under certain low-memory conditions.
In addition to performing high-speed IP forwarding, fast switching implements many other features at the interrupt level. For example, infrastructure access control lists (iACL), policy routing, and IP multicast routing are all supported in fast switching. Not all features are supported by fast switching, however, and it may need to be disabled. (Disabling fast switching causes the router to fall back to process switching.) For example, you may need to disable fast switching when debugging and packet-level tracing are required.
Like process switching, fast switching is platform-independent and is used on all native Cisco routers. In Cisco IOS, fast switching is enabled by default. You can verify that fast switching is enabled and view the routes that are currently in the fast switching cache. As you can see in Example 1-1, the interface Serial4/1 has fast switching enabled. Example 1-2 shows the contents of the fast-switching cache. As you can see, each entry includes the destination prefix, age that the prefix has been in the cache, egress interface, and next-hop layer IP address.
Example 1-1 Verifying that Fast Switching Is Enabled
R1# show ip interface Serial4/1 Serial4/1 is up, line protocol is up Internet address is 10.0.0.1/30 Broadcast address is 255.255.255.255 Address determined by non-volatile memory MTU is 4470 bytes Helper address is not set Directed broadcast forwarding is disabled Outgoing access list is not set Inbound access list is not set Proxy ARP is enabled Security level is default Split horizon is enabled ICMP redirects are always sent ICMP unreachables are always sent ICMP mask replies are never sent IP fast switching is enabled IP fast switching on the same interface is enabled IP Flow switching is disabled IP CEF switching is enabled IP Fast switching turbo vector IP Normal CEF switching turbo vector IP multicast fast switching is enabled IP multicast distributed fast switching is disabled IP route-cache flags are Fast, CEF Router Discovery is disabled IP output packet accounting is disabled IP access violation accounting is disabled TCP/IP header compression is disabled RTP/IP header compression is disabled Probe proxy name replies are disabled Policy routing is disabled Network address translation is disabled WCCP Redirect outbound is disabled WCCP Redirect inbound is disabled WCCP Redirect exclude is disabled BGP Policy Mapping is disabled
Example 1-2 Viewing the Current Contents of the Fast-Switching Cache
R1# show ip cache IP routing cache 3 entries, 480 bytes 4088 adds, 4085 invalidates, 0 refcounts Minimum invalidation interval 2 seconds, maximum interval 5 seconds, quiet interval 3 seconds, threshold 0 requests Invalidation rate 0 in last second, 0 in last 3 seconds Last full cache invalidation occurred 8w0d ago Prefix/Length Age Interface Next Hop 10.1.1.10/32 8w0d Serial0/0 10.1.1.10 10.1.1.128/30 00:00:10 Serial0/2 172.17.2.2 10.1.1.132/30 00:10:04 Serial0/1 172.17.1.2 R1#
From an IP traffic plane perspective, it should be clear that fast switching is mainly meant to accelerate the forwarding of data plane traffic. This works well in higher-speed networks when the packets are simple, data plane packets. However, not all features or packets can be fast switched. When this is the case, forwarding reverts to process switching, which adversely impacts router performance. This makes it all the more critical to classify traffic planes and to protect the router resources as network speeds increase and routers see higher packet rates (pps). When traffic fits the normal, fast switching profile, the router should perform well. However, if the traffic changes (for example, under malicious conditions) and process switching is required, the router could experience resource exhaustion and impact the overall network conditions. Let’s take a look at each traffic plane again from the perspective of fast switching:
Data plane: Fast switching operations were developed to speed delivery of data plane traffic, as Figure 1-12 illustrates. Packets will be fast switched when the destination is transit and a cache entry already exists. When a cache entry does not exist, for example, for the first packet of each new flow, process switching must be used to determine the next hop and Layer 2 header details. Preventing spoofed or malicious packets from abusing the data plane will keep the router CPU and fast cache memory from being abused. As with process switching, additional processing is required to handle data plane IP exception packets as well. For example, TTL = 0 packets must be dropped and an ICMP error message must be generated and transmitted back to the originator. Packets with IP options may also require additional processing to fulfill the invoked option. When the ratio of exception packets becomes large in comparison to normal transit packets, router resources can be exhausted, potentially affecting network stability. These and other concepts are explored further in Chapter 2. Chapter 4 explores in detail the concepts for protecting the data plane.
Control plane: Control plane packets with transit destinations are fast switched exactly like data plane transit packets. Control plane packets with receive destinations and non-IP exception packets (for example, Layer 2 keepalives, IS-IS, and so on) follow the same initial fast-switching operations illustrated in Figure 1-12. However, once packet identification determines these are receive or non-IP packets, they are handed off to the CPU for processing by the appropriate software elements, and additional resources are consumed to fully process these packets. Thus, regardless of the switching method invoked, receive and non-IP control plane packets must be processed by the CPU, potentially causing high CPU utilization. High CPU utilization can result in dropped traffic if the router is unable to service forwarding requests. It is critical to prevent spoofed and other malicious packets from impacting the control plane, potentially consuming router resources and disrupting overall network stability. Chapter 5 explores these concepts in detail.
Management plane: Management plane packets with transit destinations are fast switched exactly like data plane transit packets. Management plane packets with receive destinations follow the same initial fast-switching operations described for the control plane. Once these packets are identified, they are handed off to software elements in the CPU responsible for the appropriate network management service. Management plane traffic should not contain IP exception packets (again, MPLS OAM being one exception), but may contain non-IP (Layer 2) exception packets (generally in the form of CDP packets). Under normal circumstances, management plane traffic should have little impact on CPU performance. It is possible that some management actions, such as conducting frequent SNMP polling or turning on debug operations, or the use of NetFlow may cause high CPU utilization. Because management plane traffic is handled directly by the CPU, the opportunity for abuse makes it critical that management plane security be implemented. Chapter 6 explores these concepts in detail.
Services plane: Services plane packets follow the same initial fast switching operations illustrated in Figure 1-12. However, services plane packets generally require special processing by the router. Examples include performing encapsulation functions (for example, GRE, IPsec, or MPLS VPN), or performing some QoS or policy routing function. Some of these operations can be handled by fast switching and some cannot. For example, policy routing is handled by fast switching, while GRE encapsulation is not. When packets cannot be handled by fast switching, forwarding reverts to process switching because these packets must be handled by software elements in the CPU. When this occurs, services plane packets can have a large impact on CPU utilization. The main concern then is to protect the integrity of the services plane by preventing spoofed or malicious packets from impacting the CPU. Chapter 7 explores these concepts in detail.
The growth of the Internet has led Internet core routers to support large routing tables and to provide high packet-switching speeds. Even though fast switching was a major improvement over process switching, it still has deficiencies:
Fast switching cache entries are created on demand. The first packet of a new flow needs to be process switched to build the cache entry. This is not scalable when the network has to process switch a considerable amount of traffic for which there are no cache entries. This is especially true for BGP-learned routes because they specify only next-hop addresses, not interfaces, requiring recursive route lookups.
Fast switching cache entries are destination based, which is also not scalable because core routers contain a large number of destination addresses. The memory size used to hold the route cache is limited, so as the table size grows, the potential for cache memory overflow increases. In addition, as the depth of the cache increases, so does the lookup time, resulting in performance degradation.
Fast switching does not support per-packet load sharing among parallel routes. If per-packet load sharing is needed, fast switching must be disabled and process switching must be used, resulting in performance degradation.
In addition, the “one CPU does everything” approach was also found to no longer be adequate for high-speed forwarding. New high-end Cisco routers were developed to support a large number of high-speed network interfaces, and to distribute the forwarding process directly to the line cards. As a solution for these and other issues, Cisco developed a new switching method—Cisco Express Forwarding (CEF). CEF not only addresses the performance issues associated with fast switching, but also was developed with this new generation of “distributed” forwarding platforms in mind as well.
Cisco Express Forwarding
CEF, like fast switching, uses cache entries to perform its switching operation entirely during a route processor interrupt interval (for CPU-based platforms). As you recall, fast switching depends on process switching for the first packet to any given destination in order to build its cache table. CEF removes this demand-based mechanism and dependence on process switching to build its cache. Instead, the CEF table is pre-built directly from the routing table, and the adjacency table is pre-built directly from the ARP cache. These CEF structures are pre-built, before any packets are switched. It is never necessary to process switch any packet to get a cache entry built. Once the CEF tables are built, the CPU on the route processor is never directly involved in forwarding packets again (although it may be required to perform memory management and other housekeeping functions). In addition, pre-building the CEF structures greatly improves the forwarding performance on routers with large routing tables. Note that CEF switching is often referred to as “fast path” switching.
There are two major structures maintained by CEF:
Forwarding Information Base (FIB)
Adjacency table
Forwarding Information Base
The FIB is a specially constructed version of the routing table that is stored in a multiway tree data structure (256-way MTrie) that is optimized for consistent, high-speed lookups (with some router and IOS dependence). Destination lookups are done on a whole-byte basis; thus it takes only a maximum of four lookups (8-8-8-8) to find a route for any specific destination.
The FIB is completely resolved and contains all routes present in the main routing table. It is always kept synchronized. When routing or topology changes occur in the network, the IP routing table is updated, and those changes are reflected in the FIB. Because there is one-to-one agreement between FIB entries and routing table entries, the FIB contains all known routes and eliminates the need for the route cache maintenance associated with fast switching.
Special “receive” FIB entries are installed for destination addresses owned by the router itself. These include addresses assigned to physical interfaces, loopback interfaces, tunnel interfaces, reserved multicast addresses from the 224.0.0.0/8 address range, and certain broadcast addresses. Packets with destination addresses matching “receive” entries are handled identically by CEF, and simply queued for local delivery.
Each FIB entry also contains one or more links to the entries in the adjacency table, making it possible to support equal-cost or multipath load balancing.
Adjacency Table
The adjacency table contains information necessary for encapsulation of the packets that must be sent to given next-hop network devices. CEF considers next-hop devices to be neighbors if they are directly connected via a shared IP subnet.
Each adjacency entry stores pre-computed frame headers used when forwarding a packet using a FIB entry referencing the corresponding adjacency entry. The adjacency table is populated as adjacencies are discovered. Each time an adjacency entry is created, such as through the ARP protocol, a link-layer header for that adjacent node is pre-computed and stored in the adjacency table.
Routes might have more than one path per entry, making it possible to use CEF to switch packets while load balancing across multiple paths.
In addition to next-hop interface adjacencies (in other words host-route adjacencies), certain exception condition adjacencies exist to expedite switching for nonstandard conditions. These include, among others: punt adjacencies for handling features that are not supported in CEF (such as IP options), and “drop” adjacencies for prefixes referencing the Null0 interface. (Packets forwarded to Null0 are dropped, making an effective, efficient form of access filtering. Null0 will be discussed further in Section II).
Example 1-3 shows the output of the show adjacency command, displaying adjacency table information. Example 1-4 shows the output of the show ip cef command, displaying a list of prefixes that are CEF switched.
Example 1-3 Displaying CEF Adjacency Table Information
R1# show adjacency Protocol Interface Address IP Serial4/0 point2point(7) IP Tunnel0 point2point(6) IP POS5/0.1 point2point(9) IP POS5/0.2 point2point(5) IP FastEthernet0/2 10.82.69.1(11) IP FastEthernet0/2 10.82.69.82(5) IP FastEthernet0/2 10.82.69.103(5) IP FastEthernet0/2 10.82.69.220(5) R1#
Example 1-4 Displaying CEF FIB Table Information
R1# show ip cef Prefix Next Hop Interface 0.0.0.0/0 12.0.0.2 Serial4/1 0.0.0.0/32 receive 10.0.0.0/8 10.82.69.1 FastEthernet0/0 10.82.69.0/24 attached FastEthernet0/0 10.82.69.0/32 receive 10.82.69.1/32 10.82.69.1 FastEthernet0/0 10.82.69.82/32 10.82.69.82 FastEthernet0/0 10.82.69.121/32 receive 10.82.69.220/32 10.82.69.220 FastEthernet0/0 10.82.69.255/32 receive 172.0.0.0/30 attached Serial4/1 172.0.0.0/32 receive 172.0.0.1/32 receive 172.0.0.3/32 receive 172.12.12.0/24 attached Loopback12 172.12.12.0/32 receive 172.12.12.12/32 receive 172.12.12.255/32 receive 192.168.100.0/24 172.0.0.2 Serial4/1 224.0.0.0/4 drop 224.0.0.0/24 receive R1#
CEF Operation
CEF switching is enabled globally using the ip cef global configuration mode command, after which CEF switching is enabled on all CEF-capable interfaces by default. CEF can be enabled or disabled on a per-interface basis. CEF must be enabled on the ingress interface (whereas fast switching is enabled on the egress interface) to CEF switch packets, because CEF makes the forwarding decision on ingress. Use the interface configuration mode command ip route-cache cef to enable CEF, or the no version of the same command to disable CEF on the ingress interface.
A distributed version of CEF is available for the 7500, 7600, and Cisco 12000 routers. On the Cisco 12000 GSR, CEF is enabled by default and in fact is the only version of switching available on that platform although multiple forwarding paths exist within the router architecture.
Each time a packet is received on a CEF-enabled interface, the CEF process forwards the packet, as illustrated in Figure 1-13 and explained next:
CEF switching begins exactly like the other switching methods. First, the network interface hardware receives the packet and transfers it into I/O memory. The network interface interrupts the CPU, alerting it to the ingress packet waiting in I/O memory for processing. IOS updates its inbound packet counters.
The IOS interrupt software inspects the packet header information (encapsulation type, network layer header, and so forth) and determines that it is an IP packet. Instead of placing the packet on the input queue for CPU processing, however, the interrupt software consults the FIB for an entry matching the destination address. If an entry exists, the interrupt software retrieves the pre-built Layer 2 header information from the adjacency table, and builds the packet for forwarding. Finally, the interrupt software alerts the outbound interface.
The outbound network interface hardware senses the packet, dequeues it from I/O memory, and transmits it on to the network.
If the destination address is not found in the FIB, instead of reverting to fast switching and then process switching, CEF simply drops the packet which causes a CPU hit for the resultant ICMP destination unreachable (type 3) generation. Fast switching has no visibility into the routing table. It depends on process switching to build the fast cache on the fly. Thus, fast switching can never assume that if a destination prefix does not exist in the cache, the packet has an unreachable destination. CEF, however, pre-builds the FIB based on the routing table. Thus, if no entry exists in the FIB, then a valid destination prefix never will be found, regardless of switching mechanisms. This is one of the best features of CEF; no processor load is expended for unresolved destinations.
Illustration of CEF Switching
From an IP traffic plane perspective, CEF switching primarily not only helps accelerate the forwarding of transit data plane traffic, but also performs consistent operations for many other packet types. This is exactly what is needed for building and running higher-speed networks with high packet rates. All traffic planes and packet types exist in any network, not to mention malicious packets. All of these packet types must be handled within the network, but not all of these packets can be CEF switched. When this is the case, routers must invoke alternate processing functions, often impacting performance. It is most critical in networks to classify traffic planes and protect router resources. Let’s take a look at each traffic plane again from the perspective of CEF switching:
Data plane: CEF switching operations were developed to speed delivery of data plane transit traffic. These packets will be CEF switched when a FIB entry exists and will be dropped when a FIB entry does not exist. Dropping packets with unresolved destinations gives CEF a tremendous advantage over other switching methods because no CPU involvement is necessary simply to drop these packets. You should be aware, however, that dropping these packets does cause the generation of an ICMP unreachable error message. On most routers, ICMP packets are generated by the CPU. Thus, even with CEF switching, some CPU impacts can be seen when high rates of ICMP unreachable messages are generated. As you will learn in Chapter 4, ICMP unreachable message generation can be rate-limited or disabled. Preventing spoofed or malicious packets from abusing the data plane will also help protect router and network resources. As with other switching methods, additional processing is required to handle data plane exception packets as well. For example, TTL = 0 packets must be dropped and reply ICMP error messages must be generated and transmitted. Packets with IP options may also require additional processing to satisfy the invoked option. CEF does use special adjacencies to switch these types of packets to the appropriate handlers, which means the CPU is not involved in the switching portion of the operation. Nonetheless, the CPU may be required to process these packets after CEF. When the ratio of exception packets becomes large in comparison to normal transit packets, router resources can be taxed, potentially affecting network stability. These and other concepts are explored further in Chapter 2. Chapter 4 explores in detail the concepts for protecting the data plane.
Control plane: Control plane packets with transit destinations are CEF switched exactly like data plane transit packets. Control plane packets with receive destinations and non-IP exception packets (for example, Layer 2 keepalives, IS-IS, and so on) are switched by special adjacencies in CEF to the CPU for processing. Additional resources are consumed to fully process these packets. Thus, regardless of the switching method invoked, receive and non-IP control plane packets must be processed by the CPU, potentially causing high CPU utilization. High CPU utilization could affect the synchronization of CEF tables (for example, when routing table updates must be computed), resulting in dropped traffic. It is critical to prevent spoofed and other malicious packets from impacting the control plane, potentially consuming router resources and disrupting overall network stability. Chapter 5 explores these concepts in detail.
Management plane: Management plane packets with transit destinations are CEF switched exactly like data plane transit packets. Management plane packets with receive destinations are switched by special adjacencies in CEF to the CPU for processing. Additional resources are consumed to fully process these packets and provide the appropriate network management service. Management plane traffic should not contain IP exception packets (again, MPLS OAM being one exception), but may contain non-IP (Layer 2) exception packets (generally in the form of CDP packets). Under normal circumstances, management plane traffic should have little impact on CPU performance. It is possible that some management actions, such as conducting frequent SNMP polling or turning on debug operations, or the use of NetFlow may cause high CPU utilization. High CPU utilization could affect the synchronization of CEF tables (for example, when routing table updates must be computed), resulting in dropped traffic. Because management plane traffic is handled directly by the CPU, the opportunity for abuse makes it critical that management plane security be implemented. Chapter 6 explores these concepts in detail.
Services plane: Services plane packets generally require special processing by the router. Examples include things like performing some encapsulation function (for example, GRE, IPsec, or MPLS VPN), or performing some QoS or policy routing function. Some of these operations can be handled by CEF switching and some cannot. If a feature or encapsulation is not supported in CEF, the packet is passed to the next switching level (for most routers this would be fast switching), which tries to switch the packet by using its cache. If it cannot be switched at the interrupt level, the packet is placed into the IP processing queue for direct CPU handling. CEF fails to switch packets only because of unsupported features. When this occurs, services plane packets may have a large impact on CPU utilization. The main concern then is to protect the integrity of the services plane by preventing spoofed or malicious packets from impacting the CPU. Chapter 7 explores these concepts in detail.
General IP Router Architecture Types
Now that the main switching methods available in IOS today have been reviewed, and the impact of various IP traffic planes on their operation and performance has been described, it is worth looking at the various hardware architectures used in Cisco routers. Although most Cisco routers implement all of the switching methods described in the previous section, some do not. In addition, hardware variations lead to different performance levels for each of the IP traffic planes. Thus, it is important to understand the performance envelop for each platform inserted in the network. This section gives special attention to the way in which malicious traffic can affect router hardware architectures.
Increases in performance and the demand for integrated services have driven substantial changes in router hardware. Most Cisco routers use only one active route processor, even if more than one is installed. Thus, processing is done in one central location. Some routers incorporate specialized ASIC hardware to accelerate switching performance. Still others use distributed hardware architectures to achieve the highest forwarding rates.
The following sections provide general overviews of the basic hardware architectures used by Cisco routers today. These architectures are covered in sufficient detail to provide a good understanding of how various IP traffic planes impact their performance. Many excellent references provide much deeper insights into router architectures. Check the “Further Reading” section at the end of this chapter for specific recommendations.
Centralized CPU-Based Architectures
The architecture used by the original Cisco routers, and several generations of enterprise-class routers that have followed, is the centralized CPU-based design. Routers in this category that you will find in service today include the 800, 1600, 1700, 2500, 2600, 3600, RPM-PR, and 3700 series models. The long-lived 7200 series and the newer 1800, 2800, and 3800 series Integrated Services Routers (ISR) also use a centralized CPU-based architecture.
Centralized CPU-based architectures rely on a single CPU to perform all functions required by the router. This includes such functions as the following:
Supporting all networking functions, such as running and maintaining routing protocols and cache states, link states, interfaces and global counters, error packet (ICMP) generation, and other network control functions
Supporting all packet forwarding and processing functions, including applying all services such as access lists, NAT, QoS, and so on as might be applied to packets during the forwarding process
Supporting all housekeeping functions, such as servicing configuration and management functions, including command-line configuration, SNMP and syslog support, and other device management functions
All of these (and other) functions are handled within Cisco IOS Software. Cisco IOS is a monolithic operating system; all software modules are statically compiled and linked at build time, operating in a run-to-completion model within a single address space. In this kind of model, faults in one function can cause disruptions in other functions. In the previous section you learned about three different kinds of switching methods, each of which has different levels of interaction and, hence, impact on the CPU.
A typical centralized CPU-based architecture is shown in Figure 1-14. Advances in bus architecture, memory size and speed, and CPU processor performance and the addition of specialty, task-oriented chipsets have led to improvements in overall router performance. However, even with these advances and additions, centralized CPU-based devices will always be limited in overall performance given the processing constraints of the CPU-based architecture.
As illustrated in Figure 1-14, the central CPU provides support for router maintenance (CLI, management functions, and so on), for running the routing protocols, and for computing the FIB and adjacency tables described in the previous section. The FIB and adjacency table information is stored in memory attached to the CPU. All packets transiting the router (in other words, that ingress and egress through various interfaces) are processed within the CPU interrupt process if CEF is capable of switching the packet. Packets that cannot be handled by CEF are punted (switched out of the fast path) for direct handling by the CPU in software processing (slow path). Packets in this group include all receive packets, which under normal conditions means control plane, management plane traffic, plus all exception IP and non-IP packets.
Routers in this category are still quite adequate for most small to medium-sized enterprise locations where low bandwidth but rich, integrated service requirements are found. These routers represent an excellent trade-off between acceptable performance, application of integrated services, and cost. Their lack of capacity for high-speed service delivery and dense aggregation solutions means that other architectures must be explored.
Centralized CPU-Based Router Architecture
Centralized ASIC-Based Architectures
As network demands increased, CPU-based architectures alone were unable to provide acceptable performance levels. To overcome this shortcoming, modern centralized CPU-based platforms began to include forwarding ASICs in the architecture in order to offload some processing duties from the CPU and improve upon overall device performance. This category of devices includes the ubiquitous Catalyst 6500 switch family, the Cisco 7600 router family, the Cisco 7300 and RPM-XF PXF-based routers, and the Cisco 10000 Edge Services Router (ESR) family. You will most frequently find these devices in large-scale aggregation environments (such as at the service provider network edge), and medium- to large-scale enterprise and data center environments where large numbers of flows and high switching rates are common.
Retaining the centralized architecture makes sense when trading off cost, complexity, and performance. Of course, the single CPU still performs many of the functions described in the preceding section, such as supporting all networking and housekeeping functions. The ASIC incorporated into the architecture provides the ability to apply very complex operations, such as access control lists (ACL), QoS, policy routing, and so on while maintaining very high-performance forwarding rates. A typical centralized ASIC-based architecture is shown in Figure 1-15, which illustrates at a high level the Cisco 10000 ESR forwarding architecture.
The Cisco 10000 ESR forwarding functions shown in Figure 1-15 are carried out in the Performance Routing Engine (PRE). The PRE includes a central CPU to support router maintenance (CLI, management functions, ICMP, and so on) and to run the routing protocols and compute the FIB and adjacency tables. Once the CPU builds these FIB and adjacency tables, this information is pushed into the Parallel Express Forwarding (PXF) ASIC structure. All packets transiting the router (in other words, that ingress and egress through various line cards) are processed by the PXF. The CPU is not involved in forwarding packets. If other services are configured, such as the application of ACLs, QoS, policy routing, and so on, they are also configured and applied in the PXF ASIC structures.
Certain packets and features cannot be processed within ASIC architectures. These packets are punted to the supporting CPU for full processing. Packets falling into this group include all receive packets, which essentially means all control plane and management plane packets, and all exception packets. ASICs are designed to perform high-speed operations on a well-defined set of packets. Buffers, memory allocations, and data operations are designed for typical packets with 20-byte IP headers, for example. Packets that include IP options in the header exceed the 20-byte limit, and thus cannot be handled in the ASIC. Packets like these are punted to the CPU for handling in the slow path, meaning their processing speed is much slower. Because the ASIC is forwarding packets independently from the CPU, some amount of punts will not impact the overall platform throughput for normal, transit traffic. However, when the rate of exceptions becomes large, forwarding performance may be impacted.
IP traffic plane security must be developed with an understanding of how forwarding is accomplished in this centralized ASIC-based architecture, including a detailed understanding of how exception packets affect the performance envelop for the platform. The mechanisms for securing each traffic plane are covered in detail in Section II.
The centralized ASIC-based architecture offers excellent trade-offs between performance, application of integrated services, and cost. Routers in this category are well suited for their intended environments. Yet they are not adequate when the very highest throughputs are required. The centralized nature of any platform limits forwarding rates to the speed of the single forwarding engine. To achieve even faster forwarding rates, different architectures must be used, specifically distributed architectures.
Centralized ASIC-Based Router Architecture
Note – Centralized ASIC-based routers may have higher performance than certain distributed CPU-based routers.
Distributed CPU-Based Architectures
Routers used in large-scale networks require not only high packet-forwarding performance, but also high port densities. High port densities reduce the overall hardware costs, as well as the operational costs because fewer devices need to be managed. These demands have constantly driven router architectures to keep pace. Two approaches can be taken to increase the forwarding speed of a router. The first, which you just learned about, is to retain the centralized processing approach but increase the CPU speed or add hardware-based (ASIC) high-speed forwarding engines. This architecture runs into limitations at some point in both maximum packet-forwarding rates and port density.
The other approach breaks the router into discrete line cards, each capable of supporting a number of network interfaces, and “distributing” the processing and forwarding functions out to each line card. In the earlier section on CEF switching, you learned that CEF pre-computes the FIB and adjacency tables, and then populates the forwarding engine with these tables. You can see how CEF is ideally suited for a distributed architecture where each line card has the intelligence to forward packets as they ingress the router. In this case, each line card is capable of switching packets, bringing the switching function as close to the packet ingress point as possible. The other component required to complete the distributed architecture is a high-speed bus or “switching fabric” to connect the line cards into what logically appears to the routing domain as a single router. Early distributed architecture systems used CPU-based forwarding engines. These early distributed CPU-based devices include the Cisco 7500 series routers and early Cisco 12000 Gigabit Switch Router (GSR) family line cards (in other words, Engine 0 and Engine 1). Figure 1-16 shows the Cisco 7500 router to illustrate the basics of the distributed CPU-based architecture.
Distributed CPU-Based Router Architecture
As illustrated in Figure 1-16, the Cisco 7500 router includes a central CPU, referred to as the Route Switch Processor (RSP), which performs all networking and housekeeping functions, such as maintaining routing protocols, interface keepalives, and so forth. Thus, all control plane and management plane traffic is handled by the RSP. The 7500 also includes multiple Versatile Interface Processors (VIP) with port adapters (PA). Using port adapters not only provides high port density but also adds flexibility in interface type through modularity. Distributed switching is supported in VIPs by their own CPUs, RAM, and packet memory. Each VIP runs a specialized IOS image. Two data transfer buses provide packet transfer capabilities between VIPs (line cards) and the RSP to support high-speed forwarding. When a PA receives a packet, it copies the packet into the shared memory on the VIP and then sends an interrupt to the VIP CPU. The VIP CPU performs a CEF lookup, and then rewrites the packet header. If the egress port is on the same VIP, the packet is switched directly. If the egress port is on a different VIP, the RSP is not required for packet processing but does spend CPU time as a bus arbiter for inter-processor communication while moving packets across the bus. VIPs can support very complex operations, such as ACLs, QoS, policy routing, encryption, compression, queuing, IP multicasting, tunneling, fragmentation, and more. Some of these are supported in CEF; others require the other switching methods.
In general, the RSP is not directly involved in forwarding packets. There are exceptions, however, just as with other router architectures. Of course, control, management, and supported services plane traffic are always punted to the RSP for direct handling. Other exceptions occur under various memory constraints, and when processing packets with specific features such as IP options, TTL expirations, and so on. Too many or inappropriate packets punting to the RSP can jeopardize the status of the entire platform. Thus, IP traffic plane security must provide the mechanisms to control how various packets affect the performance envelop of the platform.
Distributed CPU-based architectures were the first routers in this category and were the original routers used within high-speed core networks. Many of these routers are still in use today. The logical follow-on to these CPU-based designs is the current state of the art, distributed ASIC-based architecture. Distributed hardware designs are required to achieve the feature-rich, high-speed forwarding required in today’s networks.
Distributed ASIC-Based Architectures
Modern large-scale routers designed for very high-speed networks must operate with truly distributed forwarding engines capable of applying features at line rate. As you learned with centralized ASIC-based architectures, ASICs provide this capability by offloading forwarding functions from the CPU. In the centralized ASIC-based architecture, the limitations on performance were due to the use of a single ASIC for forwarding. To increase the overall platform forwarding capacity, the ASIC concept is extended into the distributed environment. In distributed ASIC-based platforms, each line card has its own forwarding ASIC that operates independently from all other line cards. In addition, by using modular line cards, high port densities and flexibility in interface type can be achieved. The Cisco 12000 family was the first to use the fully distributed ASIC-based architecture, followed by the Cisco 7600. Recently, the Carrier Routing System (CRS-1) became the latest addition to the Cisco family of fully modular and distributed ASIC-based routing systems.
To illustrate at a high level how distributed ASIC-based architectures function, review the Cisco 12000 diagram shown in Figure 1-17.
Distributed ASIC-Based Router Architecture
The Cisco 12000 includes one active main route processor, the most current version of which is the Performance Route Processor 2 (PRP). Redundant PRPs may be used but only one is active and acts as the primary. The PRP is critical to the proper operation of the whole chassis. It performs network routing protocol processing to compute FIB and adjacency table updates and distributes updates to the CEF tables stored locally on each line card. The PRP also performs general maintenance and housekeeping functions, such as system diagnostics, command-line console support, and software maintenance and monitoring of line cards. The Cisco 12000 crossbar switch fabric provides synchronized gigabit speed interconnections for the line cards and the PRP. The switch fabric is the main data path for packets that are sent between line cards, and between line cards and the PRP. Modular line cards provide the high port-density interfaces to the router. The packet-forwarding functions are performed by each line card, using a copy of the forwarding tables computed by the PRP and distributed to each line card in the system. Each line card performs an independent destination address lookup for each datagram received using its own local copy of the forwarding table. This determines the egress line card that will handle the packet, which is then switched across the switch fabric to the egress line card.
Modular line cards give flexibility to the GSR platform. Each line card contains three discrete sections:
Physical Layer Interface Module (PLIM) section: Terminates the physical connections, providing the media-dependent ATM, Packet-over-SONET (POS), Fast Ethernet, and Gigabit Ethernet interfaces.
Layer 3 Switching Engine section: Provides the actual forwarding hardware. This section handles Layer 3 lookups, rewrites, buffering, congestion control, and other support features.
Fabric Interface section: Prepares packets for transmission across the switching fabric to the egress line card. It takes care of fabric grant requests, fabric queuing, and per-slot multicast replication, among other things.
Line cards are classified by their “engine type,” referring to the generation of the forwarding engine included on the card. The first line cards, known as Engine 0 and Engine 1, are CPU-based forwarding engines and thus behave like other CPU-based routers. The next generation, Engine 2, included an early version of an ASIC within the line card to offload some of the forwarding functions from the line card CPU. Higher-speed versions with true ASIC support followed in the Engine 4 and Engine 4+ line cards. The newest line cards are the Engine 3 and Engine 5 families. These line cards use the latest generation of dedicated ASICs, which incorporate very high-speed memory known as Ternary Content Addressable Memory (TCAM) that enables all features such as the application of ACLs, QoS, policy routing, and so forth to be performed simultaneously, while maintaining high-performance forwarding. The programmability of the ASIC allows them to support feature enhancements rather easily, as well. The Engine 3 line card, also known as the IP Services Engine, is shown in Figure 1-17 to illustrate this type of distributed ASIC-based router architecture.
On the GSR, line cards are responsible for making all packet-forwarding decisions. Because the FIB is predefined and loaded on each line card, each line card has all of the information necessary to forward any packet. If the destination address is not in the FIB, the packet is simply discarded. Distributed CEF (dCEF) is the only switching method available, and fast switching and process switching are not available as fallbacks for unresolved destinations (there are not any). There are, of course, receive packets and the exception packets to consider as well, however. Packets with a “receive” adjacency are punted to the PRP for handling. These are mainly control plane and all management plane packets, which are all handled by the PRP. Other exception packets, such as TTL expires, ICMP echo requests, IP options, and so on, are handled in various ways. Some of these packets are capable of being handled directly by the line card CPU. Technically, although still considered a punt because the line card ASIC does not support processing these packets, they are still capable of being handled locally, thus protecting the RP from unnecessary packet processing. ICMP unreachable generation, for example, is handled directly by the line card CPU. Other exception packets can be handled only by the PRP. Too many or inappropriate packets punting to either the line card CPU or the PRP can be detrimental to the platform. Again, IP traffic plane security mechanisms must be provided to control how various packets affect the platform.
The newest router in the Cisco family, the CRS-1, requires its own discussion here, as it brings both evolutionary and revolutionary changes to previous router technologies. Four key elements define these architectural advances, including: 40-Gbps line cards, advanced Route Processors, a service-intelligent switch fabric, and Cisco IOS XR Software. Some of these elements are illustrated in Figure 1-18 and described next.
CRS-1 Router Architecture and 40-Gbps Line Card
Note – This is not meant to be a detailed review of the CRS-1. Such a task requires a book in itself. Additional citations to relevant CRS-1 and IOS XR documents are given in the “Further Reading” section at the end of this chapter.
The first key feature illustrated in Figure 1-18 is the new 40-Gbps line card design. Each line card is separated by a midplane into two main components: the interface module (IM) and the modular services card (MSC). The IM provides the physical connections to the network, including Layer 1 and 2 functions (POS and Gigabit Ethernet). The MSC is the high-performance Layer 3 forwarding engine and is equipped with two high-performance Cisco Silicon Packet Processor (SPP) 40-Gbps ASIC devices, one for ingress and one for egress packet handling. You may also see the SPP referred to as the Packet Switching Engine (PSE) ASIC in Cisco documentation and in the output of certain router commands. Each Cisco CRS-1 line card maintains a distinct copy of the adjacency table and forwarding information databases, enabling maximum scalability and performance.
The second key feature involves the Route Processors (RP). Unlike previous routers that can have only a single active route processor, even if multiple devices are included for redundancy, the CRS-1 is able to use multiple active RPs to execute control plane features, system management, and accounting functions. Allowing multiple route processors also provides service separation capabilities through control plane (routing) segmentation, providing simplified migration paths for network convergence.
The third key feature, the service-intelligent switch fabric, provides the communications path between line cards. In brief, the switch fabric is designed with separate priority queues for unicast and multicast traffic and control plane messages. Further details are outside the scope of this book.
The last key feature for CRS-1 is the use of the new Cisco IOS XR Software. Traditional Cisco IOS is a modular, cooperative, multitasking operating system where processes execute in a shared memory space and feature sets are defined at system build time. IOS implements a single-stage forwarding architecture where forwarding decisions are made only on ingress ports or line cards. This architecture provides the appropriate performance and resource footprint for the broadest set of platforms and markets. Cisco IOS XR uses a memory-protected, micro-kernel-based software architecture designed to take advantage of the multi-CPU architecture found in the CRS-1. This micro-kernel architecture allows for maximum resource usage, no resource bottlenecks, and excellent control plane performance. Processes such as routing and signaling protocols can run on a single route processor or be distributed over multiple route processors. In addition, IOS XR implements a two-stage forwarding architecture where forwarding decisions are made on both the ingress and egress line cards, providing tremendous performance and scaling advantages. (The ingress line card FIB simply has destination addresses paired with the outgoing line card only. There is no binding to Layer 2 addresses at this point. The egress line card does a second lookup to determine Layer 2 header details.)
Note – The Cisco 12000 GSR is also able to run Cisco IOS XR Software with appropriate route processor and line card hardware installed.
It is worth noting that the CLI is different for IOS XR as compared with the traditional IOS CLI. In addition, the feature set available within IOS XR, including many of the security mechanisms, is also different than with traditional IOS. To aid in this transition, Appendix C provides a side-by-side comparison of the main security features found in the IOS version 12.0(32)S against the IOS XR equivalent features where applicable.
The CRS-1 must handle receive packets and exception packets, as any IP router is required to do. In a similar manner as the ASIC-based line cards for GSR, CRS-1 line cards are capable of handling certain packets within their SPP ASIC or local line card CPU. Receive packets in the control plane and management plane are punted to the RP for handling. Certain exception packets can be handled locally, while others can be handled only by the RP. Unlike traditional IOS, the IOS XR Software provides automatic mechanisms, such as dynamic control plane protection, for handing these packets to prevent resource abuse. Other unique mechanisms and the more familiar ones can also be used to secure IP traffic planes. Detailed descriptions of some of these mechanisms are covered in later chapters as appropriate.
Note – Many excellent references cover in more detail the significant Cisco router architectures. One such reference, Inside Cisco IOS Software Architecture, provides excellent coverage of the Cisco 7500 and Cisco 12000 GSR. A list of suggested references is provided in the “Further Reading” section at the end of this chapter.
In summary, the following can be stated about all the router architectures described in this chapter:
Data plane packet handling depends on the switching mode enabled and the router architecture. Despite the switching mode, however:
— IP options are always process switched (or handled in the slow path in the case of the GSR).
— TTL expiry packets are always process switched path (or handled in the slow path in the case of the GSR).
— The first packet of a multicast stream is always punted to create the multicast routing state on the route processor (see Chapter 2).
Control plane and management plane packets are always handled by the CPU on the route processor within the software slow path.
— ICMP replies may be handled on distributed line cards, but always by a CPU and never by an ASIC.
Services plane packets impact routers in varying ways. The specific router architecture must be considered to determine their overall impact.
Summary
This chapter introduced the concepts of IP traffic planes and their relationship to IP protocol and IP network operations. IP traffic planes were segmented into four logical groups:
Data plane: User and customer traffic
Control plane: Routing protocol and other router state traffic
Management plane: Network operations traffic
Services plane: Customer or application traffic with specialized traffic handling requirements
The basics of IP network forwarding architectures were then reviewed, with specific focus placed on how each of the IP traffic planes interact with these forwarding concepts. Finally, router hardware architecture and packet processing concepts were reviewed to illustrate how IP traffic planes can impact various platforms through resource abuse, and why IP traffic plane security is so vital for network stability and operations.
Review Questions
Name three distinguishing characteristics of the IP protocol.
What are the main challenges when services are converged on a common IP core network?
Name the four distinct types of packets seen by a router, and give an example of each.
Identify the three common switching methods used by Cisco routers when forwarding IP packets.
True or False: Data plane traffic includes all customer traffic that is subject to the standard forwarding process and includes only transit IP packets.
True or False: Control plane traffic typically includes packets generated by network elements themselves.
What are the main functions supported by the management plane?
How does the forwarding of services plane traffic differ from data plane traffic?
Identify the four basic router architecture types.
Further Reading
Bollapragada, V., C. Murphy, and R. White. Inside Cisco IOS Software Architecture. Cisco Press, 2000. ISBN: 1-57870-181-3.
Stevens, W. Richard. TCP/IP Illustrated, Volume 1. Addison-Wesley Professional, 1993. ISBN: 0-20163-346-9.
“Cisco 12000 Series Internet Router Architecture: Line Card Design.” Cisco Tech Note. (Doc. ID: 47242.) https://www.cisco.com/en/US/partner/products/hw/routers/ps167/products_tech_note09186a00801e1dbd.shtml.
“Cisco 12000 Series Internet Router Architecture: Packet Switching.” Cisco Tech Note. (Doc. ID: 47320.) https://www.cisco.com/en/US/partner/products/hw/routers/ps167/products_tech_note09186a00801e1dc1.shtml.
“Cisco Catalyst 6500 Supervisor Engine 32 Architecture.” Cisco white paper. https://www.cisco.com/en/US/products/hw/switches/ps708/products_white_paper0900aecd803e508c.shtml.
“Cisco CRS-1 Carrier Routing System Security Application Note.” Cisco white paper. https://www.cisco.com/en/US/products/ps5763/products_white_paper09186a008022d5ec.shtml.
“IP Services Engine Line Cards.” Cisco Documentation. https://www.cisco.com/univercd/cc/td/doc/product/software/ios120/120newft/120limit/120s/120s19/ise.htm.
“Parallel Express Forwarding on the Cisco 10000 Series.” Cisco white paper. https://www.cisco.com/en/US/partner/products/hw/routers/ps133/products_white_paper09186a008008902a.shtml.
“Switching Path.” Section in “Performance Tuning Basics.” Cisco Tech Note. (Doc. ID: 12809.) https://www.cisco.com/warp/public/63/tuning.html.
“Tracing a Packet from Network Ingress to Egress, or ‘The Life of a Packet.'” Cisco Tech Note. (Doc. ID: 13713.) https://www.cisco.com/warp/public/105/42.html.
Copyright © 2007 Pearson Education. All rights reserved.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
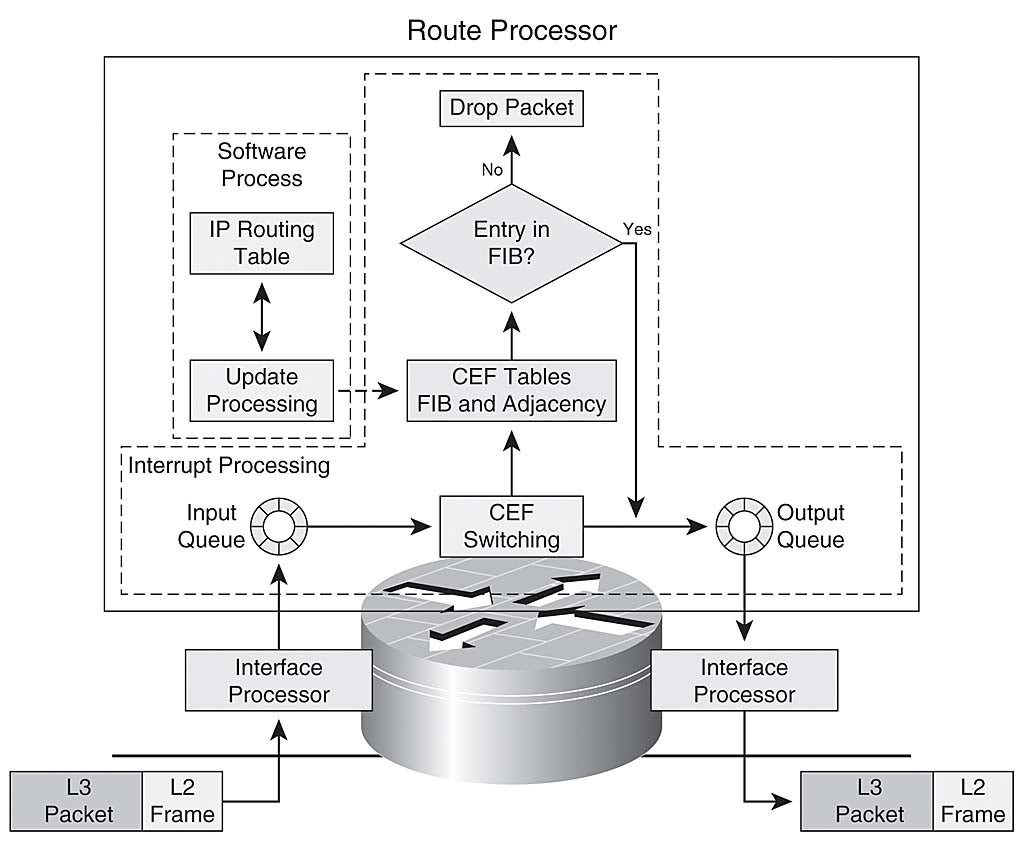{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}